

This project is a part of Mozilla Common Voice. TTS aims a deep learning based Text2Speech engine, low in cost and high in quality. To begin with, you can hear a sample synthesized voice from here.
If you are new, you can also find here a brief post about TTS architectures and their comparisons.








Text-to-Spectrogram:
Attention Methods:
- Guided Attention: paper
- Forward Backward Decoding: paper
- Graves Attention: paper
- Double Decoder Consistency: blog
Speaker Encoder:
- GE2E: paper
Vocoders:
You can also help us implement more models. Some TTS related work can be found here.
- High performance Deep Learning models for Text2Speech related tasks.
- Text2Speech models (Tacotron, Tacotron2).
- Speaker Encoder to compute speaker embeddings efficiently.
- Vocoder models (MelGAN, Multiband-MelGAN, GAN-TTS)
- Support for multi-speaker TTS training.
- Support for Multi-GPUs training.
- Ability to convert Torch models to Tensorflow 2.0 for inference.
- Released pre-trained models.
- Fast and efficient model training.
- Detailed training logs on console and Tensorboard.
- Tools to curate Text2Speech datasets under
dataset_analysis. - Demo server for model testing.
- Notebooks for extensive model benchmarking.
- Modular (but not too much) code base enabling easy testing for new ideas.
Highly recommended to use miniconda for easier installation.
- python>=3.6
- pytorch>=0.4.1
- librosa
- tensorboard
- tensorboardX
- matplotlib
- unidecode
Install TTS using setup.py. It will install all of the requirements automatically and make TTS available to all the python environment as an ordinary python module.
python setup.py develop
Or you can use requirements.txt to install the requirements only.
pip install -r requirements.txt
|- TTS/
| |- train.py (train your TTS model.)
| |- distribute.py (train your TTS model using Multiple GPUs)
| |- config.json (TTS model configuration file)
| |- tf/ (Tensorflow 2 utilities and model implementations)
| |- layers/ (model layer definitions)
| |- models/ (model definitions)
| |- notebooks/ (Jupyter Notebooks for model evaluation and parameter selection)
| |- data_analysis/ (TTS Dataset analysis tools and notebooks.)
| |- utils/ (TTS utilities -io, visualization, data processing etc.-)
| |- speaker_encoder/ (Speaker Encoder implementation with the same folder structure.)
| |- vocoder/ (Vocoder implementations with the same folder structure.)
A barebone Dockerfile exists at the root of the project, which should let you quickly setup the environment. By default, it will start the server and let you query it. Make sure to use nvidia-docker to use your GPUs. Make sure you follow the instructions in the server README before you build your image so that the server can find the model within the image.
docker build -t mozilla-tts .
nvidia-docker run -it --rm -p 5002:5002 mozilla-tts
Please visit our wiki.
Below you see Tacotron model state after 16K iterations with batch-size 32 with LJSpeech dataset.
"Recent research at Harvard has shown meditating for as little as 8 weeks can actually increase the grey matter in the parts of the brain responsible for emotional regulation and learning."
Audio examples: soundcloud
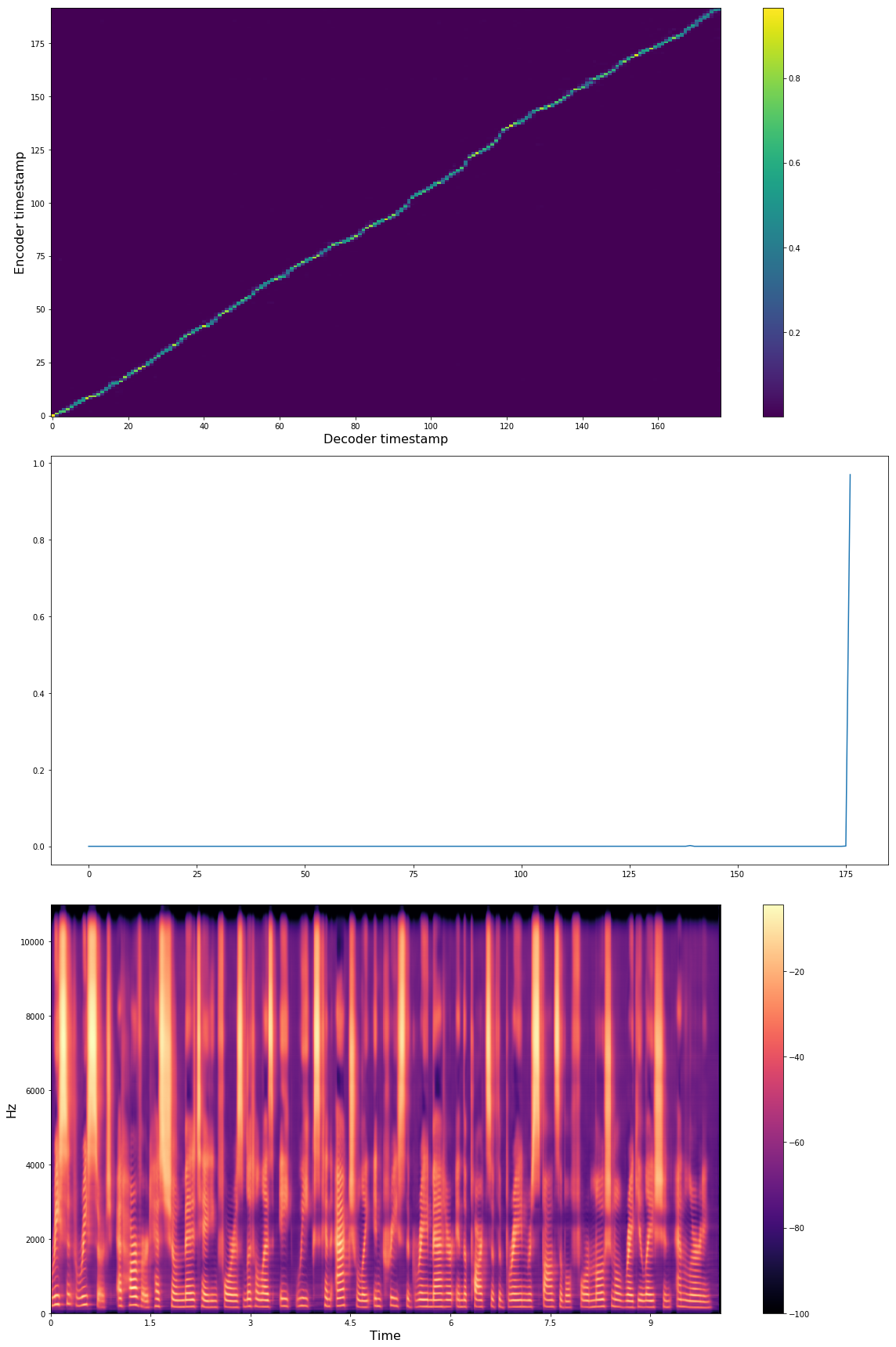
The most time-consuming part is the vocoder algorithm (Griffin-Lim) which runs on CPU. By setting its number of iterations lower, you might have faster execution with a small loss of quality. Some of the experimental values are below.
Sentence: "It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent."
Audio length is approximately 6 secs.
| Time (secs) | System | # GL iters | Model |
|---|---|---|---|
| 2.00 | GTX1080Ti | 30 | Tacotron |
| 3.01 | GTX1080Ti | 60 | Tacotron |
| 3.57 | CPU | 60 | Tacotron |
| 5.27 | GTX1080Ti | 60 | Tacotron2 |
| 6.50 | CPU | 60 | Tacotron2 |
TTS provides a generic dataloader easy to use for new datasets. You need to write an preprocessor function to integrate your own dataset.Check datasets/preprocess.py to see some examples. After the function, you need to set dataset field in config.json. Do not forget other data related fields too.
Some of the open-sourced datasets that we successfully applied TTS, are linked below.
Here you can find a CoLab notebook for a hands-on example, training LJSpeech. Or you can manually follow the guideline below.
To start with, split metadata.csv into train and validation subsets respectively metadata_train.csv and metadata_val.csv. Note that for text-to-speech, validation performance might be misleading since the loss value does not directly measure the voice quality to the human ear and it also does not measure the attention module performance. Therefore, running the model with new sentences and listening to the results is the best way to go.
shuf metadata.csv > metadata_shuf.csv
head -n 12000 metadata_shuf.csv > metadata_train.csv
tail -n 1100 metadata_shuf.csv > metadata_val.csv
To train a new model, you need to define your own config.json file (check the example) and call with the command below. You also set the model architecture in config.json.
train.py --config_path config.json
To fine-tune a model, use --restore_path.
train.py --config_path config.json --restore_path /path/to/your/model.pth.tar
For multi-GPU training use distribute.py. It enables process based multi-GPU training where each process uses a single GPU.
CUDA_VISIBLE_DEVICES="0,1,4" distribute.py --config_path config.json
Each run creates a new output folder and config.json is copied under this folder.
In case of any error or intercepted execution, if there is no checkpoint yet under the output folder, the whole folder is going to be removed.
You can also enjoy Tensorboard, if you point Tensorboard argument--logdir to the experiment folder.
This repository is governed by Mozilla's code of conduct and etiquette guidelines. For more details, please read the Mozilla Community Participation Guidelines.
Please send your Pull Request to dev branch. Before making a Pull Request, check your changes for basic mistakes and style problems by using a linter. We have cardboardlinter setup in this repository, so for example, if you've made some changes and would like to run the linter on just the changed code, you can use the follow command:
pip install pylint cardboardlint
cardboardlinter --refspec masterIf you like to use TTS to try a new idea and like to share your experiments with the community, we urge you to use the following guideline for a better collaboration. (If you have an idea for better collaboration, let us know)
- Create a new branch.
- Open an issue pointing your branch.
- Explain your experiment.
- Share your results as you proceed. (Tensorboard log files, audio results, visuals etc.)
- Use LJSpeech dataset (for English) if you like to compare results with the released models. (It is the most open scalable dataset for quick experimentation)
- Implement the model.
- Generate human-like speech on LJSpeech dataset.
- Generate human-like speech on a different dataset (Nancy) (TWEB).
- Train TTS with r=1 successfully.
- Enable process based distributed training. Similar to (https://github.com/fastai/imagenet-fast/).
- Adapting Neural Vocoder. TTS works with WaveRNN and ParallelWaveGAN (https://github.com/erogol/WaveRNN and https://github.com/erogol/ParallelWaveGAN)
- Multi-speaker embedding.
- Model optimization (model export, model pruning etc.)
- https://github.com/keithito/tacotron (Dataset pre-processing)
- https://github.com/r9y9/tacotron_pytorch (Initial Tacotron architecture)