Pytorch implementation of Transformers from paper Attention is all you need
The transformer network employs an encoder decoder architecture similar to that of an RNN. The main difference is that transformers can receive the input sentence/sequence in parallel, i.e, there is no time step associated with the input and all the words in the sentence can be passed simultaneously.
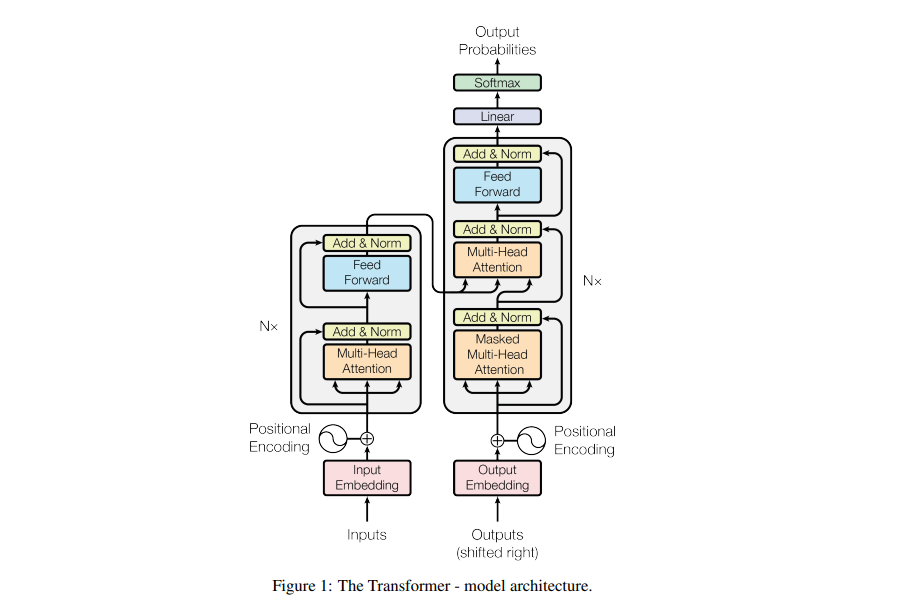
Lets begin with understanding the input to the transformer.
Consider a english to german translation. We feed the entire english sentence to the input embedding. An input embedding layer can be thought of as a point in space where similar words in meaning are physically closer to each other, i.e, each word maps to a vector with continuous values to represent that word.
Now a problem with this is that the same word in different sentences can have different meaning this is where position encoding enters.Since transformers contains no recurrence and no convolution, in order for the model to make use of the order of the sequence, it must make use of some information about the relative or absolute position of words in a sequence. The idea is to use fixed or learned weights which encode information related to a specific position of a token in a sentence.
Similarly, the target German word is fed into the output embedding and its positional encoding vector is passed into the decoder block.
The encoder block has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position- wise fully connected feed-forward network. For every word we can have an attention vector generated which captures contextual relationships between words in a sentence. Multi-headed attention in the encoder applies a specific attention mechanism called self-attention. Self-attention allows the models to associate each word in the input, to other words.
In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack. Similar to the encoder, we employ residual connections around each of the sub-layers, followed by layer normalization. The attention vectors of the german words and the attention vectors of english sentences from encoder are passed into a second multi head attention. This attention block will determine how related each word vector is with respect to each other. This is where the english to german word mapping takes place.The decoder is capped off with a linear layer that acts as a classifier, and a softmax to get the word probabilities.