![]()

![]()

SchemaSpy is a database metadata analyzer. It helps your database administrators and developers visualize, navigate and understand your data model. With an easy-to-use HTML-based report, traversing the entity-relationship diagram has never been simpler. Our product showcase is available at http://schemaspy.org/sample/index.html.
SchemaSpy is a standalone application without GUI. Just download the latest JAR file or Docker image and you're ready to go! To use SchemaSpy from Maven, please see the Maven chapter below.
# replace '6.2.4' with latest version
curl -L https://github.com/schemaspy/schemaspy/releases/download/v6.2.4/schemaspy-6.2.4.jar \
--output ~/Downloads/schemaspy.jar
For unreleased bug fixes and features-in-progress, download our snapshot JAR or use Docker tag
snapshot
SchemaSpy releases two types of JAR files: a bare-bone JAR and a fat JAR including all dependencies. Both JARs are published to Maven Central. The fat JAR is also attached to releases on GitHub. The "maven central" badge at the top of this page will take you straight to the latest version on Maven Central.
The Maven GAV of the two artifacts is as follows:
- bare-bone JAR:
org.schemaspy:schemaspy:<version> - fat JAR:
org.schemaspy:schemaspy:<version>:app← note theappclassifier
Let's assume you're using PostgreSQL (11 or later). First, download their JDBC driver.
curl -L https://jdbc.postgresql.org/download/postgresql-42.5.4.jar \
--output ~/Downloads/jdbc-driver.jar
Then run SchemaSpy against your database and you're ready to browse it in
DIRECTORY/index.html.
java -jar ~/Downloads/schemaspy.jar \
-t pgsql11 \
-dp ~/Downloads/jdbc-driver.jar \
-db DATABASE \
-host SERVER \
-port 5432 \
-u USER \
-p PASSWORD \
-o DIRECTORY
If you aren't using PostgreSQL, don't panic! Out of the box, SchemaSpy supports
over a dozen different databases. List them by using -dbhelp. Still not enough?
As long as your database has a JDBC driver you can
plug it in
to SchemaSpy.
We host our documentation on Read the Docs. Be sure to check out the section on troubleshooting common problems.
SchemaSpy covers a lot of use cases for database analysis and documentation. Be sure to check out the guides provided by the community later in this README.
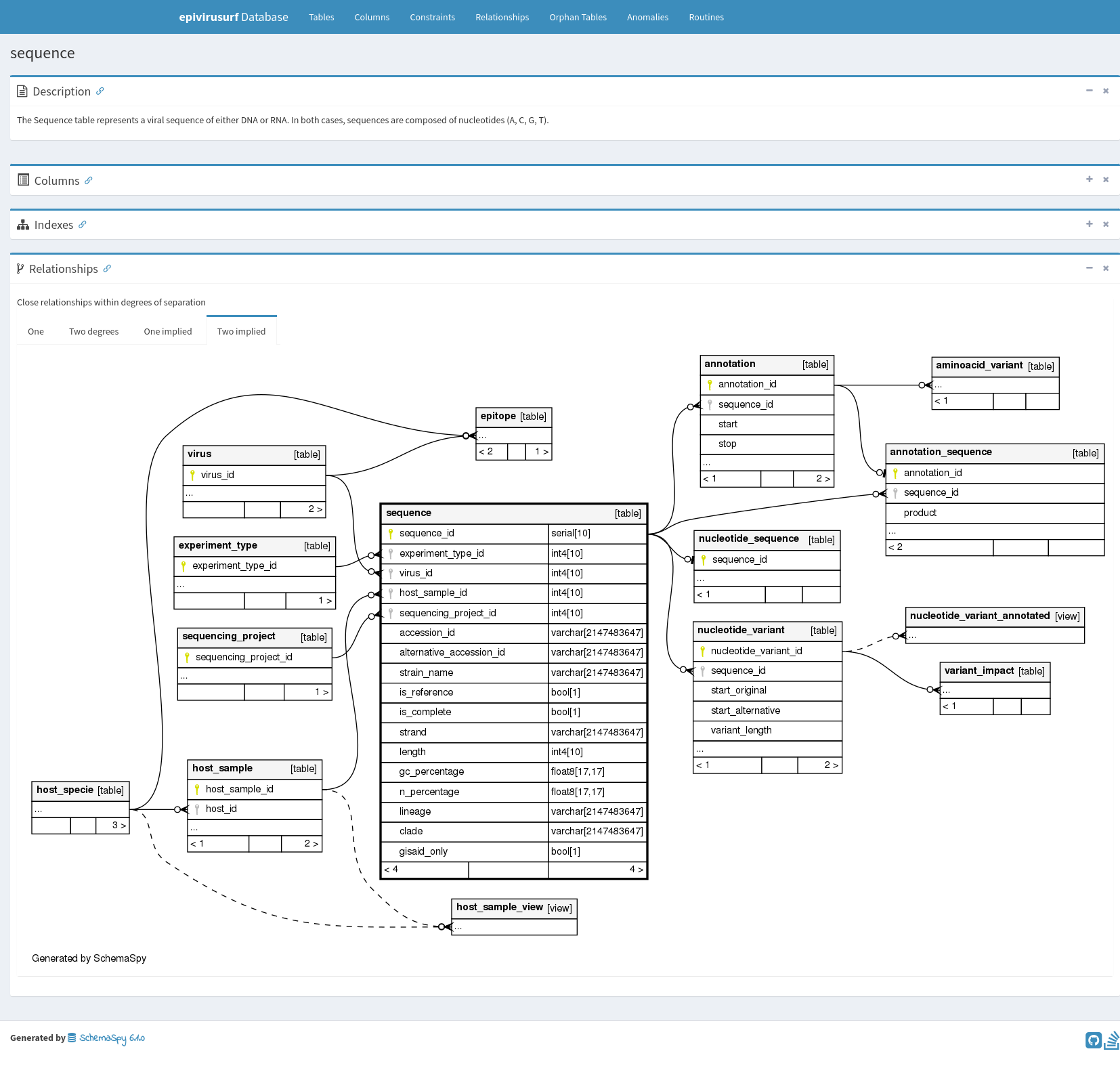
The preferred way to document databases is through entity-relationship (ER) diagrams. However, drawing these diagrams manually is such a time-consuming and error-prone process that we hardly ever draw them in practice. When the diagrams are drawn, they rarely stay up-to-date. With SchemaSpy, this is no longer a problem. The diagrams can be generated quickly and even as a part of your CI/CD workflow to ensure it's always up to date.
SchemaSpy can collect various kinds of interesting statistics to describe the shape and form of your database's structure. Drill down deeper into these statistics directly in the report or export them to excel or CSV for further QA analysis.
Nowadays, a company's data can be their most valuable asset. Since SchemaSpy only reads structural information, it works just as well on an empty database replica. This means that the report can be shared for third party analysis without fear.
SchemaSpy incorporates knowledge about best practices in database design. It can locate and report anomalies such as missing indexes, implied relationships, and orphan tables.
Welcome to the SchemaSpy community! Just reading this file or using the tool means that you're a part of our community and contributing to the future of the project. We're grateful to have you with us!
Some of our community members have put extra effort into sharing SchemaSpy with more people, asked their companies to provide financial aid, or decided to improve the software. We wish we had the space to thank each of you individually because every Github star, tweet or other activity reminds us that our work is appreciated.
For creating the first five versions of SchemaSpy:
For perpetuating SchemaSpy ever since:
For creating tutorials and guides for the community:
- 🇨🇳 SQLite 可视化SQLite数据库Schemaspy by Geek Tutorial
- 🇨🇿 Automatické vytvoření dokumentace k databázi s využitím nástroje SchemaSpy by Pavel Tišnovský
- 🇩🇪 Datenbank-Analyse mit SchemaSpy by Michael Jentsch
- 🇩🇪 Quick Tipp: Eine Datenbank Struktur verstehen mit Hilfe von schemaspy by von Irving Tschepke
- 🇪🇸
▶️ Ejemplo de Uso de schemaspy by MGS Educación, Tecnología y Juventud - 🇪🇸
▶️ Generar modelo desde una base de datos con schemaSpy by Inforgledys - 🇪🇸 Cómo documentar tus bases de datos con SchemaSpy by Jesus Jimenez Herrera
- 🇪🇸 ¿Y si documentamos la base de datos? ... SchemaSpy al rescate by Víctor Madrid
- 🇫🇷
▶️ Une DOC AUTOMATIQUE avec SchemaSpy (et SYMFONY et GITLAB) by YoanDev - 🇫🇷 Documentation automatique d’une App Symfony avec SchemaSpy et GitLab ! by YoanDev
- 🇫🇷 Documenter une base de données avec SchemaSpy by Data 4 Everyone!
- 🇯🇵 SchemaSpyでデータベースのドキュメントを生成してみた By 坂井裕介
- 🇯🇵 SchemaSpyでER図を生成する By @onozaty
- 🇵🇹
▶️ SchemaSpy - fácil de usar e já salvou meu emprego! By Dev Multitask - 🇵🇹 Documentando bancos com Schemaspy By Krisnamourt Silva
- 🇹🇭 แนะนำ SchemaSpy เครื่องมือทำเอกสาร Database by @icegotcha
- 🇻🇳 Hướng dẫn sử dụng SchemaSpy by Pham Xuan Dung
- 📖 Java Power Tools by John Ferguson Smart
- 📖 Monolith to Microservices: Sustaining Productivity While Detangling the System by Sam Newman
- Documenting your database with SchemaSpy by Robin Tegg
- Documenting your relational database using SchemaSpy by Orlando L Otero
- How to Create ERD(Entity Relationship Diagram) by Cybrosys technologies
- How to Document a Database With SchemaSpy by Data 4 Everyone!
- How to use SchemaSpy to document your database by Gustavo Ponce
- How to visualize a PostgreSQL schema as SVG with SchemaSpy by Willem van den Ende
- Installing SchemaSpy to document you database by @SimonGoring
- Netbox database schema diagram using schemaspy by Jason Lavoie
- Production grade PostgreSQL documentation in minutes by Magnus Brun Falch
- Schemaspy – create documentation for your database by Petr Hnilica
- SchemaSpy-HOWTO by @dpapathanasiou
- Simple database documentation with SchemaSpy by @rieckpil
- Use cases of data and Schemaspy: Database Management by Juilee Talele
We are proud to note that SchemaSpy assists researchers in their work.
- A data-driven dynamic ontology by Dhomas Hatta Fudholi et al.
- A large scale empirical comparison of state-of-the-art search-based test case generators by Annibale Panichella et al.
- A scientist's guide for submitting data to ZFIN by Douglas G Howe
- Automated unit test generation for classes with environment dependencies by Andrea Arcuri et al.
- BiG-SLiCE: A highly scalable tool maps the diversity of 1.2 million biosynthetic gene clusters by Satria A Kautsar et al.
- emrKBQA: A Clinical Knowledge-Base Question Answering Dataset by Preethi Raghavan et al.
- EpiSurf: metadata-driven search server for analyzing amino acid changes within epitopes of SARS-CoV-2 and other viral species by Anna Bernasconi et al.
- Experiences from performing software quality evaluations via combining benchmark-based metrics analysis, software visualization, and expert assessment by Aiko Yamashita
- FOCUSPEARL version 5.5.5 - technical description of database and interface by Maarten C Braakhekke et al.
- From monolithic systems to microservices: A decomposition framework based on process mining by Davide Taibi and Kari Systä
- GEM: The GAAIN Entity Mapper by Naveen Ashish et al.
- Healthsheet: Development of a Transparency Artifact for Health Datasets by Negar Rostamzadeh et al.
- How Aphia—The Platform behind Several Online and Taxonomically Oriented Databases—Can Serve Both the Taxonomic Community and the Field of Biodiversity Informatics by Leen Vandepitte et al.
- Incremental Control Dependency Frontier Exploration for Many-Criteria Test Case Generation by Annibale Panichella et al.
- Integrating Multimodal Radiation Therapy Data into i2b2 by Eric Zapletal et al.
- Methodology of integration of a clinical data warehouse with a clinical information system: the HEGP case by Eric Zapletal et al.
- NakeDB: Database Schema Visualization by Luis Miguel Cort ́es-Peña
- OCTOPUS database (v.2) by Alexandru T. Codilean et al.
- On approximate matching of programs for protecting libre software by Arnoldo José Müller Molina and Takeshi Shinohara
- On the Quality of Relational Database Schemas in Open-source Software by Fabien Coelho et al.
- Predicting Hospital Readmission by Analyzing Patient EHR Records by Anshik
- Prediction of actor collaborations using IMDB data by Vassilis Polychronopoulos and Abhinav Venkateswar Venkataraman
- Probabilistic relational model benchmark generation: Principle and application by Mouna Ben Ishak et al.
- Processes, Motivations, and Issues for Migrating to Microservices Architectures: An Empirical Investigation by Davide Taibi et al.
- Realising the Potential for ML from Electronic Health Records by Haoyuan Zhang et al.
- Seeding strategies in search-based unit test generation by José Miguel Rojas et al.
- Sound empirical evidence in software testing by Gordon Fraser and Andrea Arcuri
- The Zebrafish Information Network: major gene page and home page updates by Douglas G Howe et al
- Transformation and Evaluation of the MIMIC Database in the OMOP Common Data Model: Development and Usability Study by Nicolas Paris et al.
- Una base de datos espacial integrada en un Sistema de Información Geográfica para la gestión del terroir: un nuevo sistema consistente e interactivo by Alberto Lázaro-López et al.
- Using a combination of measurement tools to extract metrics from open source projects by Normi S Awang Abu Bakar and Clive Boughton
- Using Tableau Dashboards as Visualization Tool for MIMIC-III Data by Karl Gottfried et al.
- Zebrafish information network, the knowledgebase for Danio rerio research by Yvonne M Bradford et al.
To cite SchemaSpy, please use:
SchemaSpy Team (2024) SchemaSpy: Database documentation built easy. SchemaSpy. URL https://schemaspy.org/
The BibTeX entry for LaTeX users is:
@Manual{schemaspy,
title = {SchemaSpy: Database documentation built easy},
author = {{SchemaSpy Team}},
organization = {SchemaSpy},
year = {2024},
url = {https://schemaspy.org/}
}
SchemaSpy is built using maven and we utilize the maven wrapper.
Windows mvnw.cmd package
Linux ./mvnw package
The resulting application can be found in target
You need your own SonarQube:
https://hub.docker.com/_/sonarqube/
Windows mvnw.cmd -P sonar clean verify -Dsonar.host.url=http://$(boot2docker ip):9000 -Dsonar.jdbc.url="jdbc:h2:tcp://$(boot2docker ip)/sonar"
Linux ./mvnw -P sonar clean verify
Watch results at:
Linux http://localhost:9000
Windows http://$(boot2docker ip):9000
Built using Python
Create venv
Install dependencies pip install -r docs/requirements.txt
Navigate into docs
Windows make.bat clean && make.bat html
Linux make clean html
The resulting documentation can be found in docs/build/html