pgvectorscale builds on pgvector with higher performance embedding search and cost-efficient storage for AI applications.
pgvectorscale complements pgvector, the open-source vector data extension for PostgreSQL, and introduces the following key innovations for pgvector data:
- A new index type called StreamingDiskANN, inspired by the DiskANN algorithm, based on research from Microsoft.
- Statistical Binary Quantization: developed by Timescale researchers, This compression method improves on standard Binary Quantization.
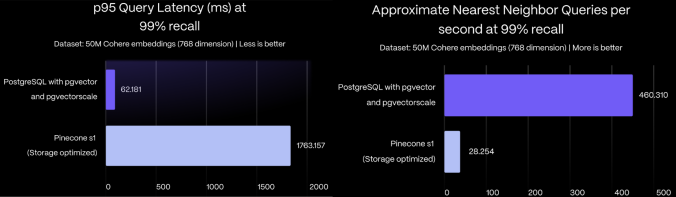
On a benchmark dataset of 50 million Cohere embeddings with 768 dimensions
each, PostgreSQL with pgvector and pgvectorscale achieves 28x lower p95
latency and 16x higher query throughput compared to Pinecone's storage
optimized (s1) index for approximate nearest neighbor queries at 99% recall,
all at 75% less cost when self-hosted on AWS EC2.
To learn more about the performance impact of pgvectorscale, and details about benchmark methodology and results, see the pgvector vs Pinecone comparison blog post.
In contrast to pgvector, which is written in C, pgvectorscale is developed in Rust using the PGRX framework, offering the PostgreSQL community a new avenue for contributing to vector support.
Application developers or DBAs can use pgvectorscale with their PostgreSQL databases.
If you want to contribute to this extension, see how to build pgvectorscale from source in a developer environment.
For production vector workloads, get private beta access to vector-optimized databases with pgvector and pgvectorscale on Timescale. Sign up here for priority access.
The fastest ways to run PostgreSQL with pgvectorscale are:
- Using a pre-built Docker container
- Installing from source
- Enable pgvectorscale in a Timescale Cloud service
-
Connect to your database:
psql -d "postgres://<username>:<password>@<host>:<port>/<database-name>" -
Create the pgvectorscale extension:
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;
The
CASCADEautomatically installspgvector.
You can install pgvectorscale from source and install it in an existing PostgreSQL server
-
Compile and install the extension
# install prerequisites ## rust curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh ## pgrx cargo install --locked cargo-pgrx cargo pgrx init --pg17 pg_config #download, build and install pgvectorscale cd /tmp git clone --branch <version> https://github.com/timescale/pgvectorscale cd pgvectorscale/pgvectorscale cargo pgrx install --release
You can also take a look at our documentation for extension developers for more complete instructions.
-
Connect to your database:
psql -d "postgres://<username>:<password>@<host>:<port>/<database-name>" -
Ensure the pgvector extension is available:
SELECT * FROM pg_available_extensions WHERE name = 'vector';
If pgvector is not available, install it using the pgvector installation instructions.
-
Create the pgvectorscale extension:
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;
The
CASCADEautomatically installspgvector.
Note: the instructions below are for Timescale's standard compute instance. For production vector workloads, we’re offering private beta access to vector-optimized databases with pgvector and pgvectorscale on Timescale. Sign up here for priority access.
To enable pgvectorscale:
-
Create a new Timescale Service.
If you want to use an existing service, pgvectorscale is added as an available extension on the first maintenance window after the pgvectorscale release date.
-
Connect to your Timescale service:
psql -d "postgres://<username>:<password>@<host>:<port>/<database-name>" -
Create the pgvectorscale extension:
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;The
CASCADEautomatically installspgvector.
-
Create a table with an embedding column. For example:
CREATE TABLE IF NOT EXISTS document_embedding ( id BIGINT PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY, metadata JSONB, contents TEXT, embedding VECTOR(1536) ) -
Populate the table.
For more information, see the pgvector instructions and list of clients.
-
Create a StreamingDiskANN index on the embedding column:
CREATE INDEX document_embedding_idx ON document_embedding USING diskann (embedding vector_cosine_ops); -
Find the 10 closest embeddings using the index.
SELECT * FROM document_embedding ORDER BY embedding <=> $1 LIMIT 10Note: pgvectorscale currently supports: cosine distance (
<=>) queries, for indices created withvector_cosine_ops; L2 distance (<->) queries, for indices created withvector_l2_ops; and inner product (<#>) queries, for indices created withvector_ip_ops. This is the same syntax used bypgvector. If you would like additional distance types, create an issue. (Note: inner product indices are not compatible with plain storage.)
The StreamingDiskANN index comes with smart defaults but also the ability to customize its behavior. There are two types of parameters: index build-time parameters that are specified when an index is created and query-time parameters that can be tuned when querying an index.
We suggest setting the index build-time paramers for major changes to index operations while query-time parameters can be used to tune the accuracy/performance tradeoff for individual queries.
We expect most people to tune the query-time parameters (if any) and leave the index build time parameters set to default.
These parameters can be set when an index is created.
| Parameter name | Description | Default value |
|---|---|---|
storage_layout |
memory_optimized which uses SBQ to compress vector data or plain which stores data uncompressed |
memory_optimized |
num_neighbors |
Sets the maximum number of neighbors per node. Higher values increase accuracy but make the graph traversal slower. | 50 |
search_list_size |
This is the S parameter used in the greedy search algorithm used during construction. Higher values improve graph quality at the cost of slower index builds. | 100 |
max_alpha |
Is the alpha parameter in the algorithm. Higher values improve graph quality at the cost of slower index builds. | 1.2 |
num_dimensions |
The number of dimensions to index. By default, all dimensions are indexed. But you can also index less dimensions to make use of Matryoshka embeddings | 0 (all dimensions) |
num_bits_per_dimension |
Number of bits used to encode each dimension when using SBQ | 2 for less than 900 dimensions, 1 otherwise |
An example of how to set the num_neighbors parameter is:
CREATE INDEX document_embedding_idx ON document_embedding
USING diskann (embedding) WITH(num_neighbors=50);You can also set two parameters to control the accuracy vs. query speed trade-off at query time. We suggest adjusting diskann.query_rescore to fine-tune accuracy.
| Parameter name | Description | Default value |
|---|---|---|
diskann.query_search_list_size |
The number of additional candidates considered during the graph search. | 100 |
diskann.query_rescore |
The number of elements rescored (0 to disable rescoring) | 50 |
You can set the value by using SET before executing a query. For example:
SET diskann.query_rescore = 400;Note the SET command applies to the entire session (database connection) from the point of execution. You can use a transaction-local variant using LOCAL which will
be reset after the end of the transaction:
BEGIN;
SET LOCAL diskann.query_search_list_size= 10;
SELECT * FROM document_embedding ORDER BY embedding <=> $1 LIMIT 10
COMMIT;pgvectorscale is still at an early stage. Now is a great time to help shape the direction of this project; we are currently deciding priorities. Have a look at the list of features we're thinking of working on. Feel free to comment, expand the list, or hop on the Discussions forum.
Timescale is a PostgreSQL cloud company. To learn more visit the timescale.com.
Timescale Cloud is a high-performance, developer focused, cloud platform that provides PostgreSQL services for the most demanding AI, time-series, analytics, and event workloads. Timescale Cloud is ideal for production applications and provides high availability, streaming backups, upgrades over time, roles and permissions, and great security.