{kind=link}
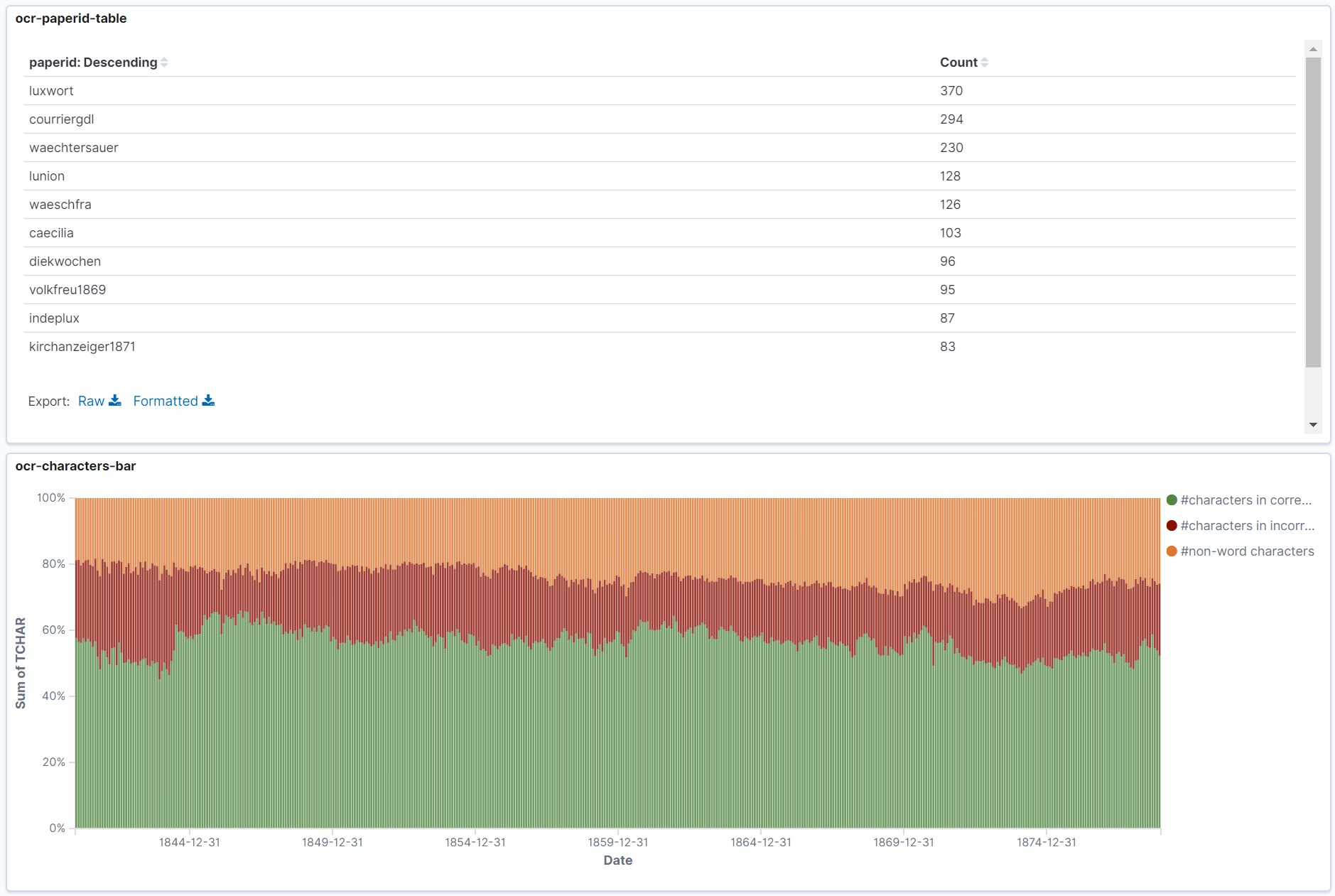
Evaluate OCR correctness by identifying the language and then running a spell checker
- npm init
- put the list of files to analyse into files.txt
- run `node index.js
- langid.py if wanted
- elasticsearch / kibana for pushing the data
- jq for formatting output from elasticsearch
Download https://data.bnl.lu/open-data/digitization/newspapers/export01-newspapers1841-1878.zip from the eluxemburgensia open data set as source data.
Using https://github.com/CLD2Owners/cld2/ As an alternative, use https://pypi.org/project/langid/
Using hunspell with dictionaries from Libreoffice and spellchecker.lu