Releases: PaddlePaddle/Paddle-Lite
v2.14-rc
Release Notes
重要更新
- 适配 PaddleX 套件 4 个场景 8 个 Paddle 3.0 beta 的模型,支持在端侧 Arm CPU 和基于 OpenCL 的 GPU 推理:
- PaddleClas:PP-LCNet_x1_0、MobileNetV3_small_x1_0
- PaddleDetection:PicoDet-S、PicoDet-L
- PaddleSeg:PP-LiteSeg-Tiny
- PaddleOCR:PP-OCRv4-mobile-rec、PP-OCRv4-mobile-det、picodet_layout_1x
BUG 修复
- 支持 0 维 tensor。#10282 #10275 #10254 #10260 #10265 #10243 #10214 #10147
- 修复 swish 算子 beta 属性缺失而导致模型加载后 core 的问题。 #10516
- 修复 benchmark 输出 tensor 默认使用 FP32 精度的问题。 #10500
- 修复 cpu 按频率排序错误的问题。 #10518
- 修复 tensor SetData jni long 类型接口签名问题。#10457
- 解决 GCC4.85 编译报错问题。 #10379
- 修复 predictor clone 后没有共享 weight 的问题。#10310
- 修复 OpenCL 3.0 环境运行报错的问题。#10280
- 优化 reduce arm cpu kernel 实现,支持输入最多 6 维。#10148
- 修复 temporal_shift 算子 shift_ratio 属性问题。#10177
- 修复 conv1d weight 错误问题。#10163
- calib 支持 INT8/FP32/FP16 多精度间转换。#10128
- 增加 host 端 atan2 和 log1p 算子。#10114
- 修复 flatten 算子不支持 XShape 可选。#10088
- 新增 host 端 empty 和 ceil 算子。#10092
v2.13-rc
Release Notes
重要更新
- 易用性提升: Windows、Linux、macOS 新增支持 Python 3.9/3.10,提供 x86 平台 Python 3.7/3.8/3.9/3.10 wheel 包,利用 pip install paddlelite==2.13rc0 安装使用;新增 Linux、macOS aarch64 架构的 opt 工具。
- 性能优化:优化 Transformer 类模型在 Arm CPU 的性能,ERNIE 3.0-Medium,ERNIE 3.0-Mini,ERNIE 3.0-Micro,ERNIE 3.0-Nano INT8 模型在多种机型性能提升 30%~100%。
- 新硬件支持:MTK APU 新增支持 MT8188 芯片,适配 Picodet 与 TinyPose FP32 模型。
框架升级
- Windows、Linux、macOS 等系统下支持并提供 Python 3.7/3.8/3.9/3.10 wheel 包。
- 新增支持外部 API 用于设置自定义 Allocator。 #10013
- 优化 config.set_model_from_buffer(const char *buffer, size_t length) 实现,buffer 的生命周期由用户侧管理,不再额外拷贝一份,减少内存开销。#10026
- 支持新量化格式 weight 不量化的算子,如conv2d、conv2d_transpose 等算子如果 weight 没有量化则仍运行浮点后端。 #10093
- 修复新量化格式对 weight 进行 per-layer 量化的支持。 #10097
- 简化性能 Profiler 工具输出,增加一键式模型性能 Profile 工具。 #10047 #10064
- 常量折叠 pass 支持更多数据类型。#9940
性能优化
- 优化 Arm CPU MaxPoolings1 通用实现和 Conv3x3s1p1在 INT8 精度实现。#9806 #9833

- 优化 Transformer 类模型在 Arm CPU 的性能。

- 具体方案(以 ERNIE 3.0-Mini 为例,左侧是经过 PaddleSlim 量化后的模型结构,右侧是 Paddle Lite 针对 Attention 结构算子融合后的结果)

- 具体方案(以 ERNIE 3.0-Mini 为例,左侧是经过 PaddleSlim 量化后的模型结构,右侧是 Paddle Lite 针对 Attention 结构算子融合后的结果)
硬件支持
-
CPU
- 特性
- 新增 Arm Android 端硬件浮点性能评估工具。#10075
- 算子、模型
- Arm 端新增 viterbi_decode 算子。 #10066 #10101
- 新增 Armv7 后端 FP16 精度 elementwise div kernel,修复 FP16 类型转换代码错误。 #10050
- Arm 端新增 Linear_interp/Linear_interp_v2 实现。 #9983
- Host 端新增 Pad 算子。 #10081
- Host 端新增 unique 算子。 #9819 #9908 #9928
- Host 端新增 empty、ceil 算子。 #10092
- Host 端新增 bitwise_and、bitwise_or、bitwise_xor、bitwise_not 算子。 #10062
- Host 端新增 temporal_shift 算子。 #10010
- Host 端新增 atan2、log1p 算子。 #10114
- BUG 修复
- 特性
-
OpenCL
-
昆仑芯 XPU
- 特性
- 重构了 XPU thread_local 的实现。 #9817
- 算子、模型
- 新增 spatial_transformer 融合算子。 #10054
- 新增 GEGLU 融合算子。 #10038
- 新增 multi-head self/cross attention 融合算子。 #10037
- silu/sin/cos/slice 算子支持 FP16 数据类型。 #10025
- 新增 group_norm + silu 融合算子。 #10022
- 优化 D2H/H2D 性能。 #9987
- 新增 mask_adaptive 算子以及相关融合 pass。 #9970
- 新增 conv2d_scale 融合 pass。 #9946
- vitstr/maskocr 支持 dynamic reshape的图 pattern,bn 支持 FP16,conv2d 融合支持 gelu 激活。 #9942
- 昆仑2、昆仑3 平台上使能 __xpu__conv2d_transpose_fuse_pass 融合 pass。 #9890
- 更换 multiclass_nms 绑定的 xdnn 算子,放宽了部分参数的限制。 #9862
- 优化 PPYOLO_dcn_2x 模型性能。 #9849 #9850
- roformer 模型的 squeeze2/reshape2 算子融合优化。 #9810
- 修改昆仑1上 gru_unit 算子以支持 pre_hidden 参数。 #9797
- matmul 增加 int8 数据类型支持。 #9764
- 新增 __xpu__quick_gelu 算子支持,并且会与 __xpu__multi_encoder 算子进行融合,优化针对 ViT 模型。 #9755
- multi_encoder 算子支持没有 mask 输入的实现。 #9712
- 新增 select_input kernel 实现,修复 box_coder 算子计算错误。 #9711
- 新增 adaptive_seqlen_v2_fuse_pass ,并增加对 mask datatype 的支持。 #9710
- sequence_mask kernel 新增 INT64 类型支持。 #9650
- BUG 修复
- 特性
-
昇腾 NPU
- 特性
- 算子、模型
- BUG 修复
- 文档
- 修复昇腾部署文档关于硬件支持和容器创建命令的描述错误。 #9995
-
高通 QNN
- 特性
- 新增适配高通 QNN 2.5。
- 支持设置 VTCM 大小以提升性能。
- 算子、模型
- 新增 where、sum、square、sqrt、lookup_table、gather、logical_and、logical_not、pow、strided_slice 等算子。
- 新增 ERNIE 3.0 全量化模型、ViT 模型。
- BUG 修复
- 解决模型 5-D 算子不支持的问题,通过 pass 实现 5-D 到 4-D 算子等价转换。
- 修复 matmul + elementwise_add + softmax 融合的内存越界问题。
- 特性
-
芯原 TIM-VX
- 特性
- 新增支持 YOLOv8、PP-LiteSeg、PP-HumanSeg-Lite 常量折叠。
- 算子、模型
- 新增 abs、argmax、argmin、cast、exp、instance_norm、layer_norm、log、prelu、gelu、equal、not_equal、expand_v2、greater_than、greater_equal、less_than、less_equal、stack、calib、gather、floor、square、unstack、pow、strided_slice、fill_constant、fill_any_like、norm、logical_not、logical_and、sum、where、softplus、logsoftmax、assign、floor_div、sin、lookup_table、lookup_table_v2、meshgrid 等算子。
- 新增模型(全量化模型)
- 检测:YOLOv6、YOLOv7、YOLOv8、PP-YOLOE-Plus
- 分类:PPLCNetV2、PPHGNet_tiny、EfficientNetB0
- 分割:PP-LiteSeg、PP-HumanSeg-Lite
- 特性
-
联发科 APU
- 特性
- 新增支持 MT8188 芯片,适配 Neuron Adapter 6.0。
- 新增支持 FP32 模型使用 FP16 计算。
- 算子、模型
- 新增 channel_shuffle、hard_swish、resize_linear、resize_nearest、split、sigmoid 算子。
- 新增 Picodet、TinyPose 模型。
输入尺寸 耗时(ms) Picodet FP32 1,3,192,192 11 1,3,320,320 15 TinyPose FP32 1,3,128,96 4.95 1,3,256,192 18.5
- 特性
v2.12
Release Notes
重要更新
- 易用性提升: 支持同一 FP32 模型在不同 Arm CPU 架构下运行期间动态支持 FP32 和 FP16 精度的推理,初步完成框架与 Arm CPU 计算库编译解耦。
- 量化推理: 支持 PaddleSlim 量化新格式模型,降低在不同硬件的迁移成本;新增 Armv9 和 SVE 指令支持,MobileNetV1 和 MobileNetV2 模型性能分别提升 21% 和 10% ,在 PP-LCNetV2、PicoDet-S、PPLite-Seg、ResNet50、EfficientNetB0、PP-OCRv2 reg、PP-OCRv3 reg、PP-OCRv2 mobilenet reg、PP-HumanSeg-Lite 模型上均有不同程度的性能提升。
- 新硬件支持: 新增支持高通 QNN 及 SA8295P 芯片,支持 Linux、Android、QNX 操作系统,支持 HTP 后端 INT8、FP16、INT8 和 FP16 混合精度,完成 79 个 Paddle 算子和 37 个 Paddle 模型适配,其中 HTP FP16 或 INT8 在 ResNet50 模型上的耗时分别仅为 CPU 的 1/32 和 1/128。
框架升级
- 清理部分不再维护、或已迁移、或活跃度较低的硬件代码。#9626 #9596
- 多后端和多精度支持。 #9339
- 提升模型部署易用性,即同一个库支持 FP32 模型在 Arm v8.2 架构上 FP32 和 FP16 两种精度。
- 该功能对库体积、首次运行耗时以及内存增幅影响可忽略。
- OpenCL 支持 buffer 和 image 两种 layout 以及 GPU + CPU 异构算子可配置。 #9665,#9630,#9621
- 模型优化阶段可根据算子 info,shape,输入精度等信息,将 OpenCL 不支持的算子自动切换后端为 Arm CPU 或 x86 CPU,具体改动包括以下情况
- elementwise_*,reshape2,unsqueeze2,split,slice 当输入为 persistable
- op 的输入 tensor 或者输出 tensor 维度大于 4
- elementwise_*,scale,输入 tensor 精度不为 FP16 或 float
- reduce_*, arg_max 当 keep_dim 或 keepdims 属性为 false
- split 算子输出 tensor 个数 != 2
- gather 算子输入X的维度的size != 2
- 模型优化阶段可根据用户自行设置的 op 配置文件以及 GPU 平台信息,优化模型结构,提升模型性能,通过自行配置op执行后端,提升模型使用 OpenCL 后端的覆盖度。
- 模型优化阶段可根据算子 info,shape,输入精度等信息,将 OpenCL 不支持的算子自动切换后端为 Arm CPU 或 x86 CPU,具体改动包括以下情况

INT8 量化新格式适配
- 对于携带 weight 的算子如 Conv 、Matmul 等,会在模型中 weight 输入前插入反量化 (dequantize_linear) 算子。在其激活输入前会插入量化 (quantize_linear) 和反量化 (dequantize_linear) 算子。在该算子输出位置插入量化 (quantize_linear) 和反量化 (dequantize_linear) 算子,方便预测库直接获取输出 scale 信息。 #8523
- 在对激活层算子如 max_pool、add、sigmoid 等量化时,如下图右所示,在其输入前会插入量化 (quantize_linear) 和反量化 (dequantize_linear) 算子。在该算子输出位置插入量化 (quantize_linear) 和反量化 (dequantize_linear) 算子,方便预测库直接获取输出 scale 信息。

性能优化
-
Arm CPU 性能优化
- Arm CPU 新增 Armv9 和 SVE 指令支持:conv1x1 利用 INT8 mmla 矩阵乘加速指令后,MobileNetV1 和 MobileNetV2 模型性能分别提升 21% 和 10% (测试机型为:高通 865 和 MTK 天玑 9000)。#9116,#9279,#9045

- 优化 Arm CPU FP16 精度 interpolate 双线性插值计算后端和 avg_pooling 计算后端。 #9447
- 新增 Arm CPU FP16 rnn op 计算 kernel。 #9402
- 优化 Arm CPU FP16 depthwise 卷积,当stride不相等,dilation不为1,kernel size 不为 3x3 5x5 等特殊情况。 #9318
- 优化 Arm CPU FP32 精度 5x5s1p2 max_pooling 计算后端。 #9696
- 优化 Arm CPU 通用 argmax 计算后端。 #9384
- 优化 Arm CPU 词表量化。 #9669
- Arm CPU 新增 Armv9 和 SVE 指令支持:conv1x1 利用 INT8 mmla 矩阵乘加速指令后,MobileNetV1 和 MobileNetV2 模型性能分别提升 21% 和 10% (测试机型为:高通 865 和 MTK 天玑 9000)。#9116,#9279,#9045
-
OpenCL GPU 性能优化
硬件支持
- 高通 QNN(新增)
- 特性
- 算子、模型(新增 79 个算子和 37 个模型)
- 图像分类:AlexNet、EfficientNetB0、DenseNet121、GoogLeNet、InceptionV3、InceptionV4、MobileNetV1、MobileNetV2、MobileNetV3_large_x1_0、MobileNetV3_small_x1_0、ResNet101、ResNet18、ResNet50、ResNeXt50_32x4d、SqueezeNet1_0、VGG16、VGG19、DarkNet53、DPN68、GhostNet_x1_0、HRNet_W18_C、PPLCNet_x0_25、Res2Net50_26w_4s、SE_ResNet50_vd、mobilenet_v1_int8_224_per_layer(INT8 全量化)、resnet50_int8_224_per_layer(INT8 全量化)
- 目标检测:ssd_mobilenet_v1_relu_voc_fp32_300、yolov3_darknet53_270e_coco*、yolov3_mobilenet_v1_270e_coco*、yolov3_mobilenet_v3_large_270e_coco*、yolov3_r50vd_dcn_270e_coco*、ssdlite_mobilenet_v3_small*、ssdlite_mobilenet_v3_large*、ppyolo_tiny_650e_coco*
- 自然语言处理:bert_base_uncased*、ernie_1.0*、ernie_tiny*
- 文档
- 新增用户示例文档。
- 昆仑芯 XPU
- 特性
- 算子、模型
- equal 、transpose 算子支持 int64 数据类型。#9092
- slice 算子支持 tensor array 输入。 #9134
- multi_encoder 算子支持 pre-LN。 #9159
- 新增支持 topk_v2 算子、以及 fc 融合。 #9207
- 新增支持 maskrcnn 模型。 #9261
- 添加 roi_align 算子对 lod 的支持。#9274
- 新增支持 multicalss_nms 算子。#9276、#9317
- 新增支持 generate_proposals_v2 算子。 #9290
- fc 算子支持 per channel 量化。#9323
- 新增支持 seq_softmax, seq_expand, lod_reset 算子。#9453
- 新增支持 roformer relative embedding pass。#9536
- fc 算子新增支持 matmul/matmul_v2's y_trans=true。#9427
- Bug 修复
- 修复 gather 算子 index type 为 INT64 时错误。 #9031
- 修复 slice 算子 output dims 错误。 #9057
- 修复 host 侧 tile 算子在输入shape较大时错误,并增加了 XPU 算子的绑定。 #9012
- 修复了 xpu_memory_optimize_pass 中 reshape2 的输出后接 while 算子 XPU 空间复用出错的问题。#9178
- 修复了 stack 注册 FP32 类型时的代码错误。#9204
- 修复 xpu_fc_pass 、cast、fill_any_like 算子错误。#9366
- 修正了 XPU 上 weight 权重类型推导的 bug、修复了 XPU kernel pick(跨子图以及inplace算子)时的一些 bug。#9406
- 修复 concat 算子 在输入类型为 INT64 时的一些 bug 。#9427
- 修复了 pad3d 算子所有模式都使用 constant 的错误。 #9506
- 修复了打开 XPU 编译开关时,在 Arm 环境上运行失败的问题。#9466
- 修复低版本 gcc 引起编译失败的问题。 #9152
- 昆仑芯 XTCL
- 算子、模型(新增支持 80 个算子和 31 个模型) #9368、#9473、#9593、#9603 、#9625、 #9628 、#9657
- 图像分类:AlexNet、DenseNet121、EfficientNetB0、GoogLeNet、Inception-v3、Inception-v4、MobileNet-v1、MobileNet-v2 、ResNet-18、ResNet-50、ReNet-101、ResNeXt50、SqueezeNet-v1、VGG16、VGG19、DPN63、DarkNet53、GhostNet、Res2Net50、SE_ResNet50
- 目标检测:SSD-MobileNetV1(1.8)、YOLOv3-DarkNet53、YOLOv3-MobileNetV1、YOLOv4
- 人脸检测:FaceBoxes
- 文本检测 & 文本识别 & 端到端检测识别:ch_PP-OCRv2_det、ch_PP-OCRv2_rec、ch_ppocr_server_v2.0_det、CRNN-mv3-CTC
- 推荐系统:支持NCF网络
- 视频分类:支持PP-TSN模型。 #9368、#9473、#9593、#9603 、#9625、 #9628 、#9657
- 文档
- 新增用户示例文档
- 算子、模型(新增支持 80 个算子和 31 个模型) #9368、#9473、#9593、#9603 、#9625、 #9628 、#9657
- 昇腾
- 寒武纪
- 芯原 TIM-VX
- 新增支持 YOLOv5s、PP-YOLOE-s、ShuffleNetV2、MobileNetV2、MobileNetV3 、PP-TinyPose 和 PP-PicoDet-relu6 。
- 融合 elementwise_mul+sigmoid 为 swish,提升 YOLOv5s 和 PP-YOLOEs 性能。 #9623

Bug 修复
-
Arm CPU
- 修复 gather op 对 index 类型不匹配的情况。 #9000
- 修复 matmul_v2 和 rnn 在 Arm CPU 上的 bug 。#9005 #9040
- 新增 FP16 稀疏卷积计算 Arm CPU 后端。 #9032
- 新增 FP16 scale op 在 Armv7 CPU 上的后端。 #9048
- 新增 FP32 softmax 和 gemm 在 Armv9 CPU 架构上的 sve 后端。 #9060 #9083
- 修复 split op 在 cascade_rcnn_r50_fpn_1x_coco 模型运行时报错。 #8934
- 新增 Arm linux 架构的 FP16 精度编译支持及算子修复。 #9098 #9113 #9118
- 修复 Arm CPU FP16 gemv 计算 bug。 #9084
- 新增 matmul_v2 x86 后端。 #9137
- 兼容 squeeze2 op 中的没有 Xshape 输出的情况。#9341
- 新增 INT8 Conv3x3s2 直接卷积计算在 Armv9 CPU 架构上的 sve 后端。 #9279
- 修复 Arm CPU FP16 transpose op bug。 #9272
- 修复 Arm CPU INT8 fc_fuse_pass bug。 #9267
- 修复 Arm CPU FP16 interpolate op 双线性插值 bug。 #9397
- 修复 full api 对 FP16 精度的支持。 #9654
- 修复新量化格式 quant_dequant_pass bug。 #9654
- 新增 matmul_v2 在 Armv9 架构上的 sve 后端 。#9696
- 兼容 flatten op 中的没有 Xshape 输出的情况 。#9696
- 新增 Arm CPU FP32 silu op。 #9280
- 修复 Arm CPU sdot 指令检测接口。 #9312
- 修复 Arm CPU FP16 gemv 传参错误。 #9331
- 修复 Arm CPU fp32_to_int8访存越界。 #9334
-
OpenCL GPU
- 修复 matmul lws 低端机报错。 #9475
v2.12-rc
v2.11
Release Notes
重要更新
-
新增非结构化 1x1 稀疏卷积实现,非结构化稀疏卷积 相对于稠密卷积,在 75% 稀疏下,性能有20%-40% 提升(支持int8/fp32精度计算),以下图示竖坐标默认为毫秒。
-
支持 MobileNet 系列模型,FP32 和INT8 精度模型在ImageNet数据集的精度损失<1%,性能有20%-40% 提升,在高通835上 armv8 和 armv7 性能情况如下图所示:

-
支持 PicoDet-m 系列模型,其中 PicoDet-ESNet-m 模型在 coco 数据集上的 mAP 损失1.5%,性能有 30%-50% 提升,在高通835上单线程和多线程(4线程)性能情况如下图所示:

-
-
新增半结构化 1x1 稀疏卷积实现,半结构化稀疏卷积相对非结构化稀疏卷积,性能有 5%-30% 提升(支持 int8/fp32 精度计算)
-
支持 MobileNet 系列模型,FP32 和 INT8 精度模型在 ImageNet 数据集的精度损失<1%,性能有20%-40% 提升,在高通835上armv8 和 armv7 性能情况如下图所示

-
V7 FP16 精度模型支持,相比 FP32 模型,性能有约一半提升

-
框架升级
- 新增 “全流程/多后端” 稳定性主动验证方法
AutoScanTester

- 算子示例:Conv2d 算子精度验证
- 融合方法示例:ConvBn融合精度验证
- 模型示例:MobilenetV1模型精度验证
- 性能测试工具中新增使用 ImageNet 数据集进行精度评估的功能 #7525
硬件支持
-
ARM CPU
- 算子实现完备度提升:基于 Autoscan 单测框架,全面提升算子和 Pass 实现的完备度,修复/增强 100+ 算子,20+ 个 Pass,e.g. 修复 reduce_max 计算错误、添加 cast, clip, concat, collect_fpn_proposals, conditional_block, conv2d 等 6 个OP单测等
- 算子稳定性增强:利用 valgrind 等第三方工具,完成 CPU 端读写越界/动态shape/栈空间分配不足等不常见场景问题的修复,提高 CPU 端稳定性和易用性,e.g. Android子线程下栈空间分配不足、读越界错误修复等
- V7 FP16 算子补齐,新增Mul、elementwise_add、pooling 等10+ 算子,例如: 添加mul算子、添加matmul 算子、添加V7 GEMM 优化实现、添加DepthWise卷积3x3s2实现、添加Pooling实现等
- 新增非结构化稀疏卷积 和半结构化稀疏卷积支持
-
OpenCL/Metal
-
新增 MacOS 平台 GPU 支持,支持 Apple Silicon 系列、Intel 系列 Mac/MacBook。 #7347 #7348
-
Metal 支持 iOS 9/iOS 10平台。 #7367
-
算子实现完备度提升:基于 Autoscan 单测框架,全面提升算子和 Pass 实现的完备度,修复/增强 33 个 OpenCL算子和 28 个 Metal 算子,14 个 Pass
- [OpenCL] 新增算子:layer_norm #8648,gelu #8636 ,elementwise_pow #8153 ,elementwise_floordiv #8587,tan #8083 ,expand #8078 #8302
- [OpenCL] 更新算子:conv2d支持group>1 #8499 ,conv2d_transpose/depthwise_conv2d_transpose支持group>1 #8494,conv2d_transpose/depthwise_conv2d_transpose支持dilation>1 #8429 , gridsampler #8546,fc #8465,box_coder #8400,concat #8375,split #8322,gather #8145,transpose #8477 #8341
- [OpenCL] 修复算子:grid_sampler #8541,lrn #8529,softmax #8409,pool2d #8397 #8591,matmul #8386 #8701,reshape/reshape2 #8364
- [OpenCL] 新增Pass:elementwise + relu6 融合 Pass #8731,keepdims convert pass #8319 ,conv + sigmoid pass #8490
- [Metal] 新增算子:reduce_max,reduce_min,reduce_mean,reduce_sum #8173,matmul #8062,exp #8082
- [Metal] 更新算子:slice #8470,conv2d #8496 #7689,softmax #8498,reshape #8542,conv2d_transpose #8439,reduce #8366,BatchNorm #8324,arg_max #8384,equal #8347,Hardsigmoid HardSwish #7662,split #7466,elementwise #7467,concat #7465,elementwise #7467 #7737
- [Metal] 修复算子: yolo_box 计算错误 #8575,box_coder 无法运行 #8493,concat #8345,输入维度校验错误 #8352,bilinear_interp #8285,pad2d #8232,scale #8210,relu relu6 #8082
-
-
昆仑芯
- 使用官方正式名称 “昆仑芯”(原名 “百度昆仑” ),且修改脚本中相关描述, #8091
- 新增算子:lod_array_length( #7314),conv3d( #7642),gelu( #7527)
- 更新算子API:concat( #8184),fc_batched_vsl( #7998),search_varconv( #7865),sequence_topk_avg_pooling( #7411),fc_fusion( #7029),sequence_reverse( #6798),sequence_concat( #6847),findmax,match_matrix_tensor,match_matrix_tensor( #7012),l2_norm( #7724),sequence_unpad( #7640)
- 修复bug:内存分配错误( #7498、 #7528),prior_box max_size 为 0 时报错( #8214),算子包含 inlace 属性时内存优化策略可能报错( #8213),conv_transpose 有 output_padding 时计算错误,instance_norm 没有 bias 或者 scale 时计算错误( #7642),有共享内存时内存优化报错( #7966),默认 workspace 可能释放错误( #7422),l2_norm 计算错误( #7983),多线程内存泄露问题( #8010)
-
Host
-
NNAdapter 提供 fake device 的 HAL 和 DDK sample code,支持 HAL 和 DDK 的独立编译,进一步降低厂商适配成本
- 提供 fake device 的 HAL 示例代码,厂商只需做少量的修改,便可快速完成硬件适配并调通整个模型;
- 针对部分厂商缺少类似 TensorRT 的在线组网 DDK 的问题,提供了 fake device 的 DDK 示例代码 帮助硬件厂商快速完成在线组网 DDK的开发;
- HAL 和 DDK 的示例代码同时提供在 PaddleLite-generic-demo 的 libs/PaddleLite/samples/fake_device 目录中,支持独立编译,即厂商无需与 Paddle Lite 联编即可快速产出 HAL 和 DDK。
-
昇腾 NPU
-
芯原 TIM-VX
- 新增支持芯原TIM-VX,已完成晶晨 A311D、S905D3 芯片在 Khadas VIM3/3L 开发板对 MobileNetV1 、ResNet50、SSD-MobileNetV1 fp32/int8 全量化模型的支持,理论上支持所有基于芯原 VIP 系列神经网络 IP 的芯片,包括: #7706、 #7878、 #8177、 #8331
- 晶晨:S905D3,C308X,C305X,A311D,V901D,S905X3,T962E2,T962X3
- 瑞芯微:RK1808,RK1808S0,RV1109/1126
- 恩智浦: i.MX 8M Plus
- JLQ:JA308,JA310,JA312
- 新增支持芯原TIM-VX,已完成晶晨 A311D、S905D3 芯片在 Khadas VIM3/3L 开发板对 MobileNetV1 、ResNet50、SSD-MobileNetV1 fp32/int8 全量化模型的支持,理论上支持所有基于芯原 VIP 系列神经网络 IP 的芯片,包括: #7706、 #7878、 #8177、 #8331
-
Android NNAPI
- 新增支持 Android NNAPI,完成 21 个 Paddle 算子和 MobileNetV1、ResNet50、SSD-MobileNetV1 fp32/int8 全量化模型的适配,支持 Android 8.1(Oreo) 及以上的终端设备,目前已验证部分高通、联发科 和华为麒麟的芯片,由于不同芯片厂商对 Android NNAPI 支持程度不同( 其中联发科和华为麒麟芯片性能较好),可能存在模型回退到 Android NNAPI 默认参考实现 nnapi-reference 执行而导致性能下降的问题。#8390、#8462、#8486
-
OpenVINO
性能优化
- ARM CPU
- 添加matmul/matmul_v2+elementwise_add fusion 支持,对模型性能有20%-40% 提升
- 添加FC+relu6 融合支持,对模型性能有约5%-10% 提升
- 添加conv+hardswish 融合支持,对含有该结构的模型,性能有约12%提升
- FP16 V7 GEMM 优化实现, 模型性能有约20%-30% 提升
- FP16 V7 conv 5×5 depthwise conv 3×3 s2 direct 优化实现、 FP16 V7 conv 3x3 s2 depthwise实现,模型性能有约20%-30% 提升
- ARM V7 FP16 性能数据和竞品性能对比如下图:
- FP32 VS FP16 性能,性能约有 40%~50% 提升
- Mali GPU
- NNAdapter
Bug修复
- 通过 Autoscan 单测测试方案,修复 30+ 算子/PASS 精度diff/运行crash 问题,例如:修复matmul_v2 少数case下计算错误、修复conv_transpose 部分case 下计算diff、修复 box_corder 在 "code_type" 为 "encode_center_size" 下计算diff等
- 修复自动插入 calib 时因为 device 不同找不到合适的 kernel 的问题, #8299
- 优化找不到 kernel 时的报错信息, #8203
- 修复在 arm core 大于 128 个的机器上的运行报错的问题, #7857
- 修复 __xpu__resnet_fuse_pass 匹配错误的问题, #7824
- 修复 while 涉及的 variable 可以推导出错误 place 的问题, #7315
- 修复部分 nnadapter + conv act fuse 错误的问题,#7296
- 修复部分模型 sequence_pool 参数解析错误的问题,#8374
- 修复些许读越界/栈空间分配失败错误,如Android子线程下栈空间分配不足、读越界错误修复等
- 修复matmul/matmul_v2 不支持x_dims=2,y_dims=1 的case,详见#8556
- 修复A35 上conv+leakyRelu 计算diff 错误,详见#8508
- 修复armv7 gemm c8 计算错误,详见 #8628
- 修复mul int8、matmul int8、fc int8计算错误、量化模型转换错误,详见 #7310、 #7964
- 修复由于添加a35 sgemm_c4函数带来的性能下降错误 #7094
- 修复armv8 在A53芯片上gemm错误,详见 #8509
- 修复ARM OPT找不到depthwise_conv_transpose算子的错误 #7270
- 修复ARM CV 相关函数读越界问题 #7671
- 修复ARM Android shell demo NDK23编译失败问题 #8245
- 修复ARM RNN 中间态输出错误问题 #8610
- 修复mask_rcnn和fast_rcnn在opt转换过程中报错的bug #8590
- 修复InferShapeWithCache的bug,使其支持非动态输入时,部分算子运行时只需推导一次算子shape信息 #8282
- 修复pybind中c++ tensor转化为py::array的bug #8057
- 修复cmake config过程中,部分python脚本不兼容python3导致编译失败的问题 #8834
- 修复ARM CPU 读越界错误, #7709
- 修复ARM int8 卷积单测下,多线程计算错误, #7648 #7692
- 修复ARM 动态shape 计算diff, #75...
v2.10
Release Notes
重要更新
- 新增 Apple Metal 后端支持,官方验证主流场景 ~20 个模型,性能与主流竞品基本对齐, 已经上线手机百度等产品线
- 新增 NNAdapter:飞桨推理 AI 硬件统一适配框架,实现推理框架与硬件适配解耦,降低了硬件适配门槛,缩短了适配周期
框架升级
- 编译策略升级
- 精简代码结构:按功能代码整理、清理冗余代码
- 精简编译逻辑 :合并和复用部分编译逻辑,整体 cmake 代码量降低60%
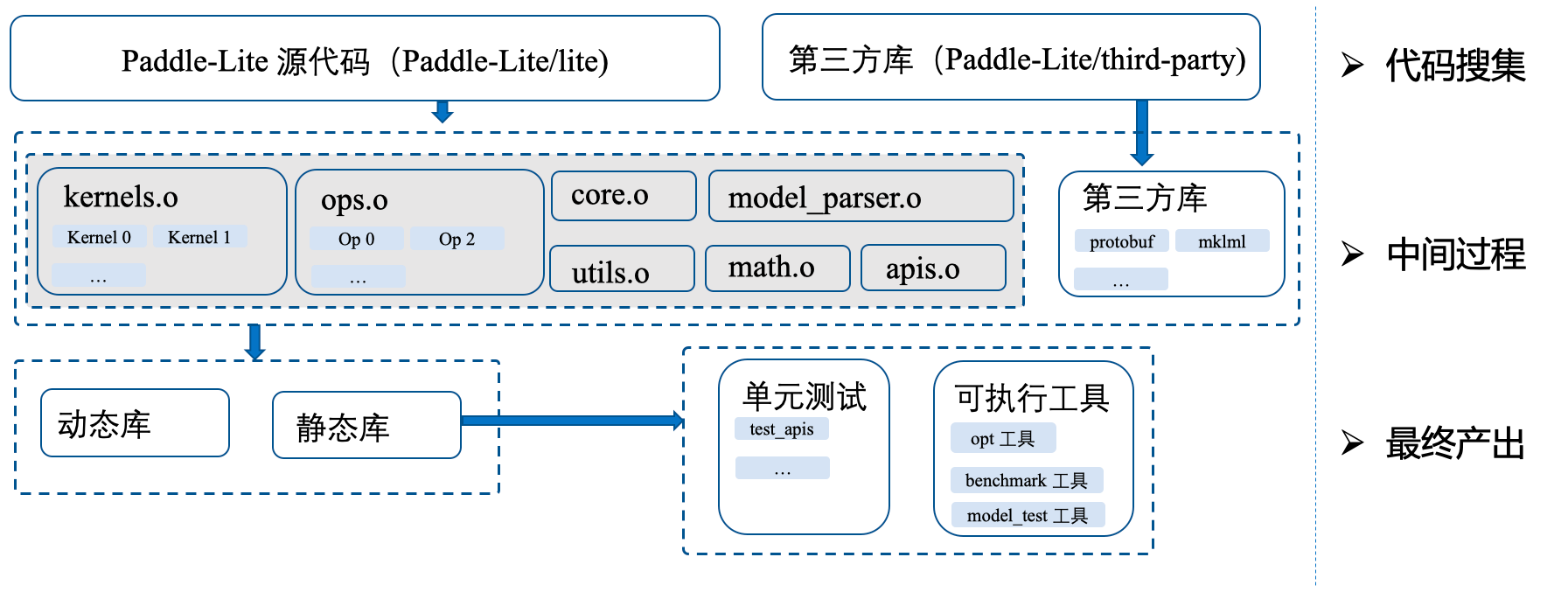
- Benchmark 工具升级
- 多平台支持
- 支持 Android 端 CPU、GPU 测速
- 支持 macOS 端(x86 架构、ARM 架构) CPU、GPU 测速
- 支持 Linux x86 端 CPU 测速
- 支持 Linux ARM 端 CPU、GPU 测速
- 多 backend 支持:已支持 CPU、GPU、各类 NPU
- 多平台支持
硬件&性能增强
ARM CPU
FP32 优化
- 新增 A53 v8 GEMM算子优化,kernel 性能有约 20%-40% 提升,详见 PR6521
- 新增 conv_3x3s2_direct C3 实现,kernel 性能有约 5%-10% 提升,详见PR6721
- 新增 A35 GEMV 算子优化实现,kernel性能有约 20%-40% 提升,详见PR6804
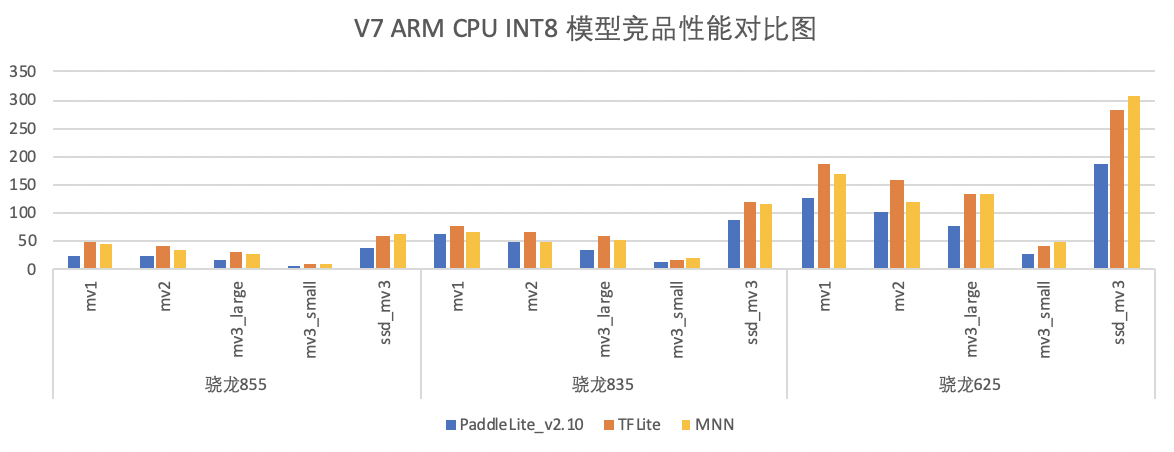
- 性能数据,以ARMv7 为例,以下为最新性能与竞品的对比:
-
FP32模型性能:低端机模型性能均优于竞品,高中端机模型性能部分优于竞品,部分差于竞品TFLite,在进一步优化中

-
INT8 模型性能:模型性能均优于竞品
-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large - ssd_mv3:
ssdlite_mobilenet_v3_large
- mv1:
-
竞品:
- PaddleLite分支:release/v2.10,7645e40(20211018)
- MNN分支:master,d21fd2a(20210904)
- TFLite分支:master,线上拉取最新(拉取日期:20210906),
- MD5 (
android_aarch64_benchmark_model) = 9851018013eb46ada7aedfad88f01da8 - MD5 (
android_arm_benchmark_model) = af6ca4bb724b9faa2370d307749f556a
- MD5 (
- TNN分支:master,40b88ce(20210903)
- MindsporeLite分支:master,155b2c0(20210830),
--cpuBindMode=1(大核)
-
FP16 优化
-
新增 V7 FP16 编译支持,要求 NDK 版本 21 及其以上
-
新增 V7 FP16 激活实现,如
relu、relu6、hard_swish等 -
新增 V7 FP16 Winograd 卷积、
calib、fill_bias_act等算子实现 -
新增
conv_3x3s2_directC3 实现,kernel 性能有5%-10% 提升,详见PR6726 -
新增 5+ V8 FP16 OP实现,如
box_clip、prior_box、hard_swish等实现 -
性能数据:
-
版本间性能对比:大部分模型有10%-30% 提升,详细性能数据请见下图

-
竞品性能对比:模型性能均优于竞品MNN 和 Mindspore-Lite,大部分模型性能与TNN 持平或稍差于,详细性能数据请见下图

-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large - ssd_mv3:
ssdlite_mobilenet_v3_large
- mv1:
-
竞品:
- PaddleLite分支:release/v2.10,7645e40(20211018)
- MNN分支:master,d21fd2a(20210904)
- TNN分支:master,40b88ce(20210903)
- MindsporeLite分支:master,155b2c0(20210830)
####基础能力支持
-
-
新增Bigru模型的支持,详见PR7212
X86
-
新增10+ OP 算子支持,如
conv_transpoe、rnn、rduce_min、pow、mish等,跑通 Paddle 2.0 50+ 模型 -
新增
elementwise的 broadcast 模式支持,详见PR6957 -
新增Bigru模型的支持,详见PR7212
-
优化卷积中 bias + act 实现,卷积性能有1-2倍的提升,详见PR6704
-
优化3x3 depthwise卷积实现,对于MobilNetV1/V2性能提升约为20%,详见PR6745
-
优化5x5 depthwise卷积实现,对于MobilNetV3 small/large性能提升超过20%,详见PR6745
-
性能数据:
-
版本间性能对比:大部分模型性能有约20%-30% 提升,详细性能数据请见下图

-
测试机:Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz
-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large
- mv1:
-
-
新增 15个 OP,包括
anchor_generator,box_clip,conv2d_transpose,clip,generate_proposals / generate_proposals_v2,group_norm,nearest_interp_v2 / bilinear_interp_v2,mish,pow,rnn,roi_align,yolo_box,reduce_min,reverse,inverse.
OpenCL
-
GPU 基础能力提升
- 新增 GPU 数据 Layout 类型:
kImageFolder#7143 - 新增 4 个 Layout 转换函数:ImageDefault -> ImageFolder、ImageFolder -> ImageDefault、ImageFolder -> NCHW、 NCHW -> ImageFolder #7143
- 新增 5 个 op:
depthwise_transpose_conv,max,argmax,abs,greater_than#6912 #6877 #6816 #6920 #6595 - 完善
elementwise,支持 broadcast #7306 #7363 - 新增 OpenCL 库体积裁剪功能 #6914
- 新增 GPU 数据 Layout 类型:
-
kernel 性能优化
- 优化 FC/Softmax:FC 可提速 1 ~ 3 倍,softmax可提速 44% ~ 302% #6560
-
Pass 相关
-
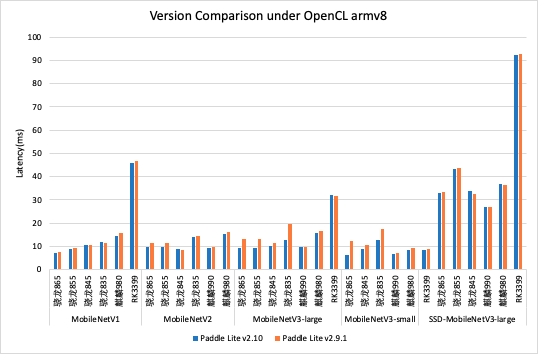
性能数据:
- 与 release/v2.9.1 版本对比,多个模型在典型设备上有 ~5% 左右的性能提升;
- 与竞品对比,在大部分模型测试场景下,Paddle Lite 领先或持平与竞品,部分模型性能有待提高。

Metal
- 新增 44 个 op&kernel , 详细列表请参考最新的 支持算子列表
- 支持 18 种 Paddle FP32 模型,已验证模型列表如下:

- 性能数据
- 与主流移动端推理框架相比,Paddle Lite 持平或者部分领先其他框架,后续将持续优化。详细数据如下:

- 与主流移动端推理框架相比,Paddle Lite 持平或者部分领先其他框架,后续将持续优化。详细数据如下:
百度昆仑 xpu
- 编译优化
- 优化编译脚本,与 Paddle 统一 xpu_toolchain 依赖
- 编译脚本支持指定环境,编译时自动下载 xpu 依赖
- 支持 Windows + XPU 的预测库编译
- 模型支持能力
- 支持带控制流算子的模型
- 支持昆仑 xpu 内存和 L3 cache 复用策略,支持部分大内存模型,模型性能提升
- kernel 和 pass 支持
- 新增
__xpu_logit等 8 个 fuse pass - 新增
less_than,argmax等 65 个 kernel,详细列表请参考最新的 支持算子列表 - 3 个 kernel 新增支持 int8 精度计算
__xpu__conv2d__xpu__fc__xpu__multi_encoder
__xpu__embedding_with_eltwise_add支持 Mask 输入和 SeqLod、PadSeqLen 输出- 支持 calib 自动精度转换
- int64 --> int32
- int32 --> int64
- kernel cast 支持输入精度为 int32、int64
- kernel concat 支持输入包含维度为 0 的 tensor,支持输入精度为 int32、int64
- 新增
硬件支持
- 新增 NNAdapter:飞桨推理 AI 硬件统一适配框架,基于标准化的推理框架适配层 API 、硬件抽象层接口定义 和 模型、算子的中间表示 实现了推理框架与硬件适配完全解耦,可较为有效的降低硬件厂商接入门槛和开发成本,而更薄的硬件适配层 不仅能以较少的代码快速完成硬件适配,还可以提高代码的可维护性。目前已完成华为麒麟 NPU、瑞芯微 NPU、联发科 APU 和 颖脉 NNA 的迁移。

- 基于 NNAdapter 新增支持华为昇腾 NPU,完成 Intel x86 + Atlas 300I/C 3010、 鲲鹏 920 + Atlas 300I/C 3000 的适配,支持 64 个算子和覆盖图像分类、目标检测、关键点检测、文本检测和识别、语义理解和生成网络共 32 个开源模型和 18 个业务模型。
- 基于 NNAdapter 新增支持晶晨NPU ,完成 Amlogic C308X (ARM Linux)、A311D(ARM Linux) 和 S905D3(Android)的适配,支持 MobileNetV1-int8-per_layer、resnet50-int8-per_layer、ssd_mobilenet_v1_relu_voc_int8_300_per_layer开源模型和人体/手部关键点检测、人脸检测/识别/关键点检测等 11 个业务模型。
- 基于 NNAdapter + 瑞芯微 NPU 在 RK1808 EVB 上完成人体关键点检测业务模型的适配。
Bug fix
- 修复 conv opencl tune bug #6879 #6734
- 修复开启内存复用后,
unsqeeze2算子报错问题 [#7384](https://github.com/Padd...
v2.10-rc
Release Notes
重要更新
- 新增 Apple Metal 后端支持,官方验证主流场景 ~20 个模型,性能与主流竞品基本对齐, 已经上线手机百度等产品线
- 新增 NNAdapter:飞桨推理 AI 硬件统一适配框架,实现推理框架与硬件适配解耦,降低了硬件适配门槛,缩短了适配周期
框架升级
- 编译策略升级
- 精简代码结构:按功能代码整理、清理冗余代码
- 精简编译逻辑 :合并和复用部分编译逻辑,整体 cmake 代码量降低60%
- Benchmark 工具升级
- 多平台支持
- 支持 android 端 cpu、gpu 测速
- 支持 macOS 端 cpu、gpu 测速
- 支持 linux x86 端 cpu 测速
- 支持 linux arm 端 cpu、gpu 测速
- 支持 android 端 cpu、gpu 测速
- 多 backend 支持:已支持 cpu、gpu、各类 NPU
- 多平台支持
硬件&性能增强
ARM CPU
FP32 优化
- 新增 A53 v8 GEMM算子优化,kernel 性能有约 20%-40% 提升,详见 PR6521
- 新增 conv_3x3s2_direct C3 实现,kernel 性能有约 5%-10% 提升,详见PR6721
- 新增 A35 GEMV 算子优化实现,kernel性能有约 20%-40% 提升,详见PR6804
- 性能数据,以ARMv7 为例,以下为最新性能与竞品的对比:
-
FP32模型性能:低端机模型性能均优于竞品,高中端机模型性能部分优于竞品,部分差于竞品TFLite,在进一步优化中
-
INT8 模型性能:模型性能均优于竞品
-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large - ssd_mv3:
ssdlite_mobilenet_v3_large
- mv1:
-
竞品:
- PaddleLite分支:release/v2.10,7645e40(20211018)
- MNN分支:master,d21fd2a(20210904)
- TFLite分支:master,线上拉取最新(拉取日期:20210906),
- MD5 (
android_aarch64_benchmark_model) = 9851018013eb46ada7aedfad88f01da8 - MD5 (
android_arm_benchmark_model) = af6ca4bb724b9faa2370d307749f556a
- MD5 (
- TNN分支:master,40b88ce(20210903)
- MindsporeLite分支:master,155b2c0(20210830),
--cpuBindMode=1(大核)
-
FP16 优化
-
新增 V7 FP16 编译支持,要求 NDK 版本 21 及其以上
-
新增 V7 FP16 激活实现,如
relu、relu6、hard_swish等 -
新增 V7 FP16 Winograd 卷积、
calib、fill_bias_act等算子实现 -
新增
conv_3x3s2_directC3 实现,kernel 性能有5%-10% 提升,详见PR6726 -
新增 5+ V8 FP16 OP实现,如
box_clip、prior_box、hard_swish等实现 -
性能数据:
-
版本间性能对比:大部分模型有10%-30% 提升,详细性能数据请见下图
-
竞品性能对比:模型性能均优于竞品MNN 和 Mindspore-Lite,大部分模型性能与TNN 持平或稍差于,详细性能数据请见下图
-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large - ssd_mv3:
ssdlite_mobilenet_v3_large
- mv1:
-
竞品:
- PaddleLite分支:release/v2.10,7645e40(20211018)
- MNN分支:master,d21fd2a(20210904)
- TNN分支:master,40b88ce(20210903)
- MindsporeLite分支:master,155b2c0(20210830)
-
X86
-
新增10+ OP 算子支持,如
conv_transpoe、rnn、rduce_min、pow、mish等,跑通 Paddle 2.0 50+ 模型 -
新增 elementwise 的 broadcast 模式支持,详见PR6957
-
优化卷积中 bias + act 实现,卷积性能有1-2倍的提升,详见PR6704
-
优化3x3 depthwise卷积实现,对于MobilNetV1/V2性能提升约为20%,详见PR6745
-
-性能数据:
-
版本间性能对比:大部分模型性能有约20%-30% 提升,详细性能数据请见下图

-
测试机:Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz
-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large
- mv1:
-
-
新增 15个 OP,包括
anchor_generator,box_clip,conv2d_transpose,clip,generate_proposals / generate_proposals_v2,group_norm,nearest_interp_v2 / bilinear_interp_v2,mish,pow,rnn,roi_align,yolo_box,reduce_min,reverse,inverse.
OpenCL
-
GPU 基础能力提升
-
kernel 性能优化
- 优化 FC/Softmax:FC 可提速 1 ~ 3 倍,softmax可提速 44% ~ 302% #6560
-
Pass 相关
-
性能数据
- 与 release/v2.9.1 版本对比,多个模型在典型设备上有 ~5% 左右的性能提升;
- 与竞品对比,在大部分模型测试场景下,Paddle Lite 领先或持平与竞品,部分模型性能有待提高。
- 对应的各框架版本如下:
- Mindspore-Lite, master, ec2942a
- MNN, master, d21fd2a
- Paddle Lite, release/v2.10, 49f9e3f
- TFLite, 线上拉取 benchmark 工具(拉取日期:20210906)
- TNN, master, 40b88ce


Metal
- 新增 44 个 op&kernel , 详细列表请参考最新的 支持算子列表
- 支持 18 种 Paddle FP32 模型,已验证模型列表如下:
百度昆仑 xpu
- 编译优化
- 优化编译脚本,与 Paddle 统一 xpu_toolchain 依赖
- 编译脚本支持指定环境,编译时自动下载 xpu 依赖
- 支持 Windows + XPU 的预测库编译
- 模型支持能力
- 支持带控制流算子的模型
- 支持昆仑 xpu 内存和 L3 cache 复用策略,支持部分大内存模型,模型性能提升
- kernel 和 pass 支持
- 新增
__xpu_logit等 8 个 fuse pass - 新增
less_than,argmax等 65 个 kernel,详细列表请参考最新的 支持算子列表 - 3 个 kernel 新增支持 int8 精度计算
__xpu__conv2d__xpu__fc__xpu__multi_encoder
__xpu__embedding_with_eltwise_add支持 Mask 输入和 SeqLod、PadSeqLen 输出- 支持 calib 自动精度转换
- int64 --> int32
- int32 --> int64
- kernel cast 支持输入精度为 int32、int64
- kernel concat 支持输入包含维度为 0 的 tensor,支持输入精度为 int32、int64
- 新增
硬件支持
- 新增 NNAdapter:飞桨推理 AI 硬件统一适配框架,基于标准化的推理框架适配层 API 、硬件抽象层接口定义 和 模型、算子的中间表示 实现了推理框架与硬件适配完全解耦,可较为有效的降低硬件厂商接入门槛和开发成本,而更薄的硬件适配层 不仅能以较少的代码快速完成硬件适配,还可以提高代码的可维护性。目前已完成华为麒麟 NPU、瑞芯微 NPU、联发科 APU 和 颖脉 NNA 的迁移。
- 基于 NNAdapter 新增支持华为昇腾 NPU,完成 Intel x86 + Atlas 300I/C 3010、 昆鹏 920 + Atlas 300I/C 3000 的适配,支持 64 个算子和覆盖图像分类、目标检测、关键点检测、文本检测和识别、语义理解和生成网络共 32 个开源模型和 18 个业务模型。
- 基于 NNAdapter 新增支持晶晨NPU ,完成 Amlogic C308X (ARM Linux)、A311D(ARM Linux) 和 S905D3(Android)的适配,支持 MobileNetV1-int8-per_layer 开源模型和人体/手部关键点检测、人脸检测/识别/关键点检测等 11 个业务模型。
- 基于 NNAdapter + 瑞芯微 NPU 在 RK1808 EVB 上完成人体关键点检测业务模型的适配。
Bug fix
- 修复 conv opencl tune bug #6879 #6734
- 修复 conv_elementwise_tree_fuse_pass bug #6812
- 修复 host topk_v2 单测 bug #6629
- 修复 ssd_box_calc_offline pass 因 concat 的输入顺序的错误而导致的某些设备运行ssd类模型时随机挂问题 #6652
- 修复 Pad3dOpLite::InferShapeImpl() bug#6824
- 修复 tile op bug 和reduce_sum op bug #6487
- 修复 conv_transpose op 的计算分配空间不足问题,详见[PR7287](https://github.com/PaddlePaddle/Pa...
v2.9.1
Release Notes
框架升级
- 新增API:
TryShrinkMemory(API文档) 用于清理临时变量,降低平均内存消耗。
API 名称: TryShrinkMemory
详细描述:
- 输入(input) : 无(NULL)
- 返回值(return) : 调用成功与否(Bool)
- 效果: 通过释放 中间变量和L3ArmCache 所占用的内存空间,降低程序静止时所消耗的内存
- opt 工具稳定性提升: 降低转换过程的可能出现错误
硬件&性能增强
ARM CPU
性能优化
- C3 conv_direct 实现,kernel 性能有约5%-15% 提升
- 优化int8
conv_depthwise_3x3实现,在 X2Paddle 转换的 tf_mobilenet v1/v2模型性能有5%-10%提升 - 添加A35 V8 GEMM优化实现,相对于A53和others实现,kernel性能有10-50%提升;在 X2Paddle 转换的 tf_mobilnet v1/v2 模型性能有20-40%提升。详细的性能数据如下:

- 修改int8 conv_winograd 实现,在ARMv8.2上,选择GEMM实现;或者用Winograd 实现。在高端机上,resent50 模型有30+% 的提升
- 当前public模型性能情况如下:


备注:
- mv1: tf_mobilnetv1
- mv2: tf_mobilnetv2
- mv3_small: tf_mobilnetv3_small
- mv3_large: tf_mobilnetv3_large
- ssd_mv3: ssdlite_mobilenet_v3_large
FP16 优化
- 添加conv_depthwise_5x5实现,在caffe_mnasnet的FP16 模型性能有一半提升
- 新增gather/transpose/elementwise_mul/interpolate/sequence_conv/Gru 等10+ FP16 OP实
- 支持检测/分类/NLP模型如tf_mobilenetv1/v2、resent_50、mobilenet_v3_ssd、ppyolo 等,其性能数据如下:


OpenCL
- kernel 性能优化
- 根据 Adreno GPU 和 Mali GPU 的特点,分别实现两套 conv 实现,在Mali GPU上提升效果明显 #6256 #6393 #6277
- 增加conv2d_1x1分块方式:由最初的H1W4C1一种分块,调整为 Adreno GPU 上的 7 种分块方式和 Mali GPU 上的 3 种分块方案。支持在预推理阶段提前Auto-Tuning试跑找到最适宜当前设备/计算规模的数据分块方式,以获得最佳的优化性能;
- 新增 winograd 实现 #6257
- 特化的 conv2d_1x1 实现:将特定情况下的 conv2d_1x1 等价为 FC,同时为了解决 input_channel 较大时单个线程需要遍历计算 input_channel 次乘累加操作,扩大了 4 倍线程数量,即将 input_channel 分成 4 部分,每个线程负责其中一部分的计算,然后 4 个线程通过 local memory 把中间乘累加结果归约在一起,同时使用访存更友好的 half16 存储权重,在MobileNetV3_small_x1_0_infer 模型上有1.3%到30%的性能提升 #6389
- 增强 pool2d:在global pooling时增加线程并行度,使用local memory归约,kernel 性能由2到24倍的提升 #6267
- 增强 concat:多输入concat 实现在 CPU 上耗时很小,但是在GPU上很容易就会成为性能瓶颈,因此实现了一个通用型 concat kernel,避免了数据类型转换,ssd_mobilenetv3-large 模型在 855 手机上有22%的性能提升 #6266
- Pass 优化
- 框架优化
MobilenetV1, SSD-MobilenetV3-large, Resnet50 模型在7种不同设备下运行耗时如下,蓝色代表最优竞品,红色代表Paddle-Lite v2.9,灰色代表本版本的Paddle-Lite:



更详细的Paddle-Lite v2.9 与Paddle-Lite v2.9.1的性能对比数据见下图:

xpu
- 新增fuse pass:
- bigru
- conv2d_affine_channel
- 新增op&kernel:
- bigru
- sequence_pad
- sequence_mask
- gru_unit
- unsqueeze
- prelu
- elementwise_max
- fill_zeros_like
- grid_sampler
- reduce_all
- reduce_any
- reduce_prod
- reduce_max
- reduce_min
- 更新xpu_toolchain依赖方式
Bug fix
- 修复host fill_any_like在dtype=-1情况下的计算逻辑
- 修复可变输入shape下,conv_winograd 计算crash 问题
- 修复部分size下,gemv_trans 计算读越界风险问题
- 修复sgemv_trans函数在IOS设备上跑crash问题
文档更新
- 更新armlinux编译环境
v2.9
Release Notes
重要更新
- 推理库体积大幅压缩及提升opt转换工具易用性
- 大幅提升Windows编译效率
- 增加ARM CPU armv8.2 fp16指令支持
- 大幅优化opencl性能
- 新增支持基于Intel FPGA海云捷迅开发板
框架升级
-
重点Feature:
-
支持
FP16低精度运行- 推理速度提升30%、内存消耗降低30%
- 当前只支持部分高端Android机型(高通865、高通835、kirin990)
-
根据模型压缩库功能: 使用说明- 根据模型信息压缩预测库体积
- 一键化脚本
cd Paddle-Lite && ./lite/tools/build_android_by_models.sh /models
- 格式化产出: 转化后模型 + opt 工具 + 压缩后的预测库
- 根据模型信息压缩预测库体积
-
模型支持Embedding量化
- Embedding权重支持int8/16存储,有效减小模型存储体积。

-
-
opt 工具易用性升级
- 自动识别模型格式(可识别以下几种格式)
- [格式1]
__model__ + var1 + var2 + etc. - [格式2]
model + var1 + var2 + etc. - [格式3]
model.pdmodel + model.pdiparam - [格式4]
model + params - [格式5]
model + weights
- [格式1]
- 简化提示信息
- 常规模式:加载信息 + 转化信息
- DEBUG 模式: 通过设置环境变量 GLOG 可以进入DEBUG模型、打印更详细的中间信息
- 常规模式:加载信息 + 转化信息
- 可查看优化后模型结构:
opt --optimize_out_type=protobuf- 用netron 查看转化后的模型结构
- 自动识别模型格式(可识别以下几种格式)
-
源码编译
- 支持更多的NDK版本: 支持 r16b ~ r20c
- windows编译:编译耗时大幅降低,减少约60%
- Docker : 更新Docker镜像(TODO)、Docker镜像体积降低30%
-
其他
- 输入格式检查:自动检查模型输入
shape\precision信息是否正确 - 支持获得int64类型的输出 #5832
- 输入格式检查:自动检查模型输入



新增算子
- correlation
- polygon_box_transform
- roi_perspective_transform
- scatter_nd_add
硬件&性能增强
ARM CPU
- 新增OP
- FP16 特性支持
- 仅在armv8.2 架构手机(如小米8、小米9等)上支持ARMv8 FP16模型推理
- 新增10+ FP16 OP算子,如:GEMM、Convolution、Pooling、Softmax、Fc 等
- 已跑通分类模型如mobilenetv1、mobilenetv2、resentv1等模型;
详细性能数据如下图:

- FP32性能优化:
- GEMM V8性能优化,对mobilenetv1 性能有5%左右提升; PR5957
详细性能数据如下图:

OpenCL
- 新增 op:
sqrt,square,rsqrt,matmul#5791 - 增强 conv2d_1x1,通过在线预计算选择最优分块方式,大部分模型普遍有10%-25%的性能提升 #6067 #5904
- 增强 conv2d_3x3,通过对 filter 数据重排,resnet50 在大部分手机上有 5%-60% 的性能提升 #5618
- 新增 5 个 pass:
- 通过 pass 精简模型结构,提高了 SSD 模型速度,adreno gpu 加速明显(855、865上有 1 倍加速),mali gpu 加速效果稍小(kirin990 和 rk3399 上分别有 25% 和 14% 的加速)#5930 #5965
- 新增 flatten_contiguous_range + fc 融合 pass,Paddle2.0 模型 mobilenetv1 在大部分手机上有 5%-10% 的性能提升 #6057
- 新增 conv + prelu 融合 pass,mtcnn_det3 模型在骁龙 865 上有 20% 的性能提升 #5461
- 新增 fc + prelu 融合 pass #5468
- 开启 elementwise + act pass #5791
- 实现
layout_cast对 5 维 tensor 的支持 #5777 - 新增定期刷新命令队列接口,默认关闭 #5905
X86
- 新增elementwise_mod #5472
- 支持bool/int32为输入的cast,支持int32 slice #5511
- 新增reduce_max #5633
- 新增reduce_prod #5692
- 新增gru_unit #5739
- 支持int32/int64 elementwise_mul #5852
- 新增instance_norm#5860
- 新增 elementwise_max, elementwise_min #5862
- 修复var_conv2d缺少COLUMN/ROW输入注册的问题 #5880
- 支持int32/int64 concat #5887
- 新增 grid_sample #5895
- 支持int32/int64 slice;新增elementwise_div #5898
- 修复concat在axis<0时的计算问题 #5917
- 新增elementwise_pow, sqrt #5928
Host
- 新增increment #5472
- 新增tril_triu #5507
- 新增polygon_box_transform #5627
- 新增beam_search_decoder #5670
- 新增roi_perspective_transform #5680
- 新增sequence_expand #5685
- 新增pad2d #5694
- 新增lod_reset #5710
- 新增distribute_fpn_proposals,collect_fpn_proposals #5760
- 新增topk #5758
- 新增beam_search #5759
- multiclass_nms支持PolyIoU #5773
- 新增split #5796
- 新增assign_value#5828
- 新增correlation #5865
- 新增sequence_pad #5867
- 新增sequence_mask #5871
昆仑 XPU
- 支持int32 slice #5488
- 支持int32/int64为输入的reshape2 #5511
- 支持int32 elementwise_add #5539
- 支持带sub_block的模型预测 #5725
- 支持CxxConfig支持预测带sub_block的模型 #5776
- 支持tensor_array类型 #5815
- 修复L3 cache可能分配不正确的问题 #5868
- elementwise类算子支持x的维度数小于y的维度数 #5906
- 修复arm下编译问题 #5997
RK NPU
- 新增norm op bridge #5926
- 新增ssd模型prior_box离线处理pass,针对SSD系列模型,Rockchip NPU、HuaweiKirinNPU、OpenCL均能获得性能提升 #5788


- 新增支持全量化模型的异构计算 #5591
硬件支持
- 新增支持基于Intel FPGA的海云捷迅开发板,目前仅支持conv2d算子的加速(其它算子均可运行在ARM核),支持SSD-MobileNetV1模型。#5742
Bug fix
- 修复 OpenCL conv+prelu 融合带来结果异常的问题 #5793
- 修复 OpenCL bilinear_interp结果错误问题 #5482
- 修复 kirin970 armv7 OpenCL运行报错问题 #5791
- 修复 armlinux 编译mobile_full demo报错问题 #6068
- 修复expand的输入为ExpandTimes和expand_times_tensor时dim错误的bug #5488
- 修复opt打印支持算子的格式问题 #5600
- 修复从内存加载模型的问题 #6004
- 修复不支持UInt8类型变量的问题#6032
- 修复int8 GEMM LeakyRelu和Relu6计算错误;#5986
- 修复group_norm不对齐paddlepaddle API的计算错误;#5683
文档更新
- 新增Paddle Lite使用Intel FPGA预测部署教程 文档和Demo
- 新增ARM CPU预测库部署和单测使用文档
v2.8
Lite v2.8 Release Notes
Release Notes
Paddle-Lite v2.8 全面支持 Paddle 2.0 模型推理,并对框架进行了内存开销优化和稳定性改进。同时,ARM CPU, OpenCL 性能相对前一版本有较大提升,增加 XPU / NPU 图优化策略,并丰富了算子类型。
框架升级
-
重点Feature:增加 “算子版本控制方法“
- 算子版本控制方法:
- 为算子(op)注册版本,对算子定义的修改会导致版本号提升
- 向下兼容:高版本支持兼容低版本
- 与PaddlePaddle API定义兼容:
- Paddle-Lite上算子定义与 Paddle1.7/1.8/2.0 API 定义兼容
- 算子版本控制方法:
-
源码编译
- Arm移动端编译(Android/iOS/ArmLinux): 耗时降低约 50%
- x86 编译(macOS/windows/Ubuntu):
- 支持静态链接 Intel MKL 库
- windows支持 MD_DynamicRelease 编译选项
- 适配低版本Android:armv7 最低支持 Android API Level 16, armv8 最低支持 Android API Level 21
-
模型转换工具(opt)
- 支持离线量化功能:原始模型体积可以压缩50%~75%,详情参考使用文档
-
初始化过程
- 内存优化:初始化过程内存峰值降低50%
- 模型加载: 增加数据校验,使加载过程更稳定
-
其他:优化 Windows x86 计时函数,降低耗时波动
新增接口
-
C++ API 接口:新增
set_x86_math_num_threads,可以设置 x86 上 MKL 底层计算的线程数 -
Python API 接口: 新增
tensor.numpy和tensor.from_numpytensor.numpy(): 将Tensor 中的数据转化为numpy.arraytensor.from_numpy():从numpy.array数据对象创建 Tensor
-
NN硬件相关 API 接口:新增
set_subgraph_model_cache_buffers接口- 支持从内存设置子图缓存产物,使用方法可参考Rockchip NPU Demo
新增算子
- bilinear_interp_v2
- nearest_interp_v2
- elementwise_min
- elementwise_floordiv
- flatten_contiguous_range
- layout_once
- lod_array_length
- sync_batch_norm
- fusion_elementwise_min_activation
- multiclass_nms3
- linspace
- argsort
- topk_v2
- where
- meshgrid
- tile
- cumsum
- gather_nd
- gather_tree
- reduce_min
支持Paddle2.0 模型
对应支持 PaddlePaddle v2.0 ,官方验证了如下模型

文档更新
- 更新X86 MKL静态库支持以及Windows编译相关文档 PaddleLite使用X86预测部署
- 新增动态离线量化完整示例
- 更新XPU文档,提供xpu_toolchain的下载
- 更新Rockchip NPU文档,demo增加Resnet-50模型的支持,提供一键全量化PaddleSlim-quant-demo 用于生成适用于Rockchip NPU的全量化MobileNetV1和Resnet-50模型
硬件&性能增强
ARM CPU
- ARM CPU支持LSTM/GRU量化的模型
- ARM CPU支持动态图量化训练功能产出的量化模型
- ARM CPU支持RNN OP算子
- ARM CPU 对卷积类算子做了性能优化,与上个版本相比FP32 模型性能有5%-10%提升:
- 优化A53 处理器上卷积-GEMM 矩阵乘kernel的实现;
- 优化其他卷积kernel的实现,如Im2col_GEMM 、conv_3x3s2_direct 等卷积算子;
- ARM CPU支持高版本NDK编译
- ARMLinux支持使用环境变量CC和CXX设置C编译器和C++编译器
- ARM CPU INT8性能提升:
- 基于NDK17在armv7下支持dot指令,在ARMv8.2架构下,GEMM性能有大幅提升(实测A76有150%-270%提升)
- 重构GEMV INT8实现,在各架构下均有较大提升,平均提升100+%-200+%
- ARM CPU 使用Intrinsic优化box_coder,增加对paddle fastrcnn和maskrcnn模型的支持
- ARM CPU相对于上一个版本,绝大部分模型性能均有较大提升


OpenCL
- OpenCL 的多平台支持:新增支持 Windows/macOS 平台,可利用 PC 端的集成显卡或独立显卡提高预测速度
- OpenCL 的多精度运行执行:新增支持 fp32 精度,主要用于对精度要求较高的应用场景
- OpenCL op 支持范围:新增
reduce_mean,hard_swish,prelu,batch_norm,clip,yolo_box,shape,slice - OpenCL op 通用性增强算子:
transpose,conv2d; - OpenCL 在线auto-tune新增2种online-auto-tune策略
CL_TUNE_RAPID、CL_TUNE_NORMAL,更快调优模型性能; - OpenCL 增加对Buffer和Imaeg2D的内存边界检查,在用户输入尺寸较大导致运行失败情况下会有友好的提示;
- OpenCL 增加scale-activation、conv-scale、conv-hard sigmoid、instance_norm-relu 融合,可以对包含该结构的模型有性能提升如Yolov3-Mobilenetv3;
- OpenCL depthwise_conv2d3x3 强化:支持 stride 不一致时的计算
v2.8 版本与 v2.7 版本相比,绝大部分模型都有性能提升


昆仑 XPU
- XPU增强
conv2d的融合,新增多种模式的xpu_conv2d的融合 - XPU增强
pool2d:支持adaptive参数,支持全部类型的padding - XPU增强
multi_encoder的融合:支持融合slice - XPU新增
softmax和topk的融合
RK NPU
- Rockchip NPU新增reshape, flatten, scale, pad2d, transpose 等 op bridge,修复act, concat, batch norm 等 op bridge 中的问题
- 针对Rockchip NPU全量化模型,新增pass实现多输入op(如concat)的输入、输出scale的一致性约束
- Rockchip NPU新增支持Resnet-50和度目业务模型(CV检测和识别类)
- Rockchip NPU支持离线模型缓存,支持从内存读入缓存后的模型,满足模型加、解密的业务要求
已支持的MobileNetV1和ResNet-50全量化模型分别在TB-RK1808S0 AI计算棒、RK1808 EVB开发板和RV1109开发板的CPU和NPU性能(耗时)对比如下

硬件支持
- 新增Imagination NNA 芯片的支持,增加文档和demo
Bug fix
- 修复了 X86 在Windows上的预测库编译错误以及X86 Demo编译错误,以及Win32编译修复
- 修复 ARM CPU
sequence_conv、pool2x2pool1x1小概率报错问题 - 修复 ARM CPU
conv_depthwise、conv_winograd、transpose`在模型输入shape变化情况下,小概率报错问题。 - 修复 OpenCL
avg pool2d、instance_norm、elementwise_add计算结果错误的问题 - 修复 OpenCL concat 多输入情况下的内存泄露问题
- 修复 windows 开启 profile 后crash问题
- 修复
compareOP推理输出shape的错误 - 修复unstack在融合后出现输出tensor数量错误的问题
- 修复对Android7.0(含)以上版本的检查部分手机厂商如魅族系统限制库使用的系统库,在使用cpu模型会挂在cpu+gpu库里的情况