v2.10-rc
Release Notes
重要更新
- 新增 Apple Metal 后端支持,官方验证主流场景 ~20 个模型,性能与主流竞品基本对齐, 已经上线手机百度等产品线
- 新增 NNAdapter:飞桨推理 AI 硬件统一适配框架,实现推理框架与硬件适配解耦,降低了硬件适配门槛,缩短了适配周期
框架升级
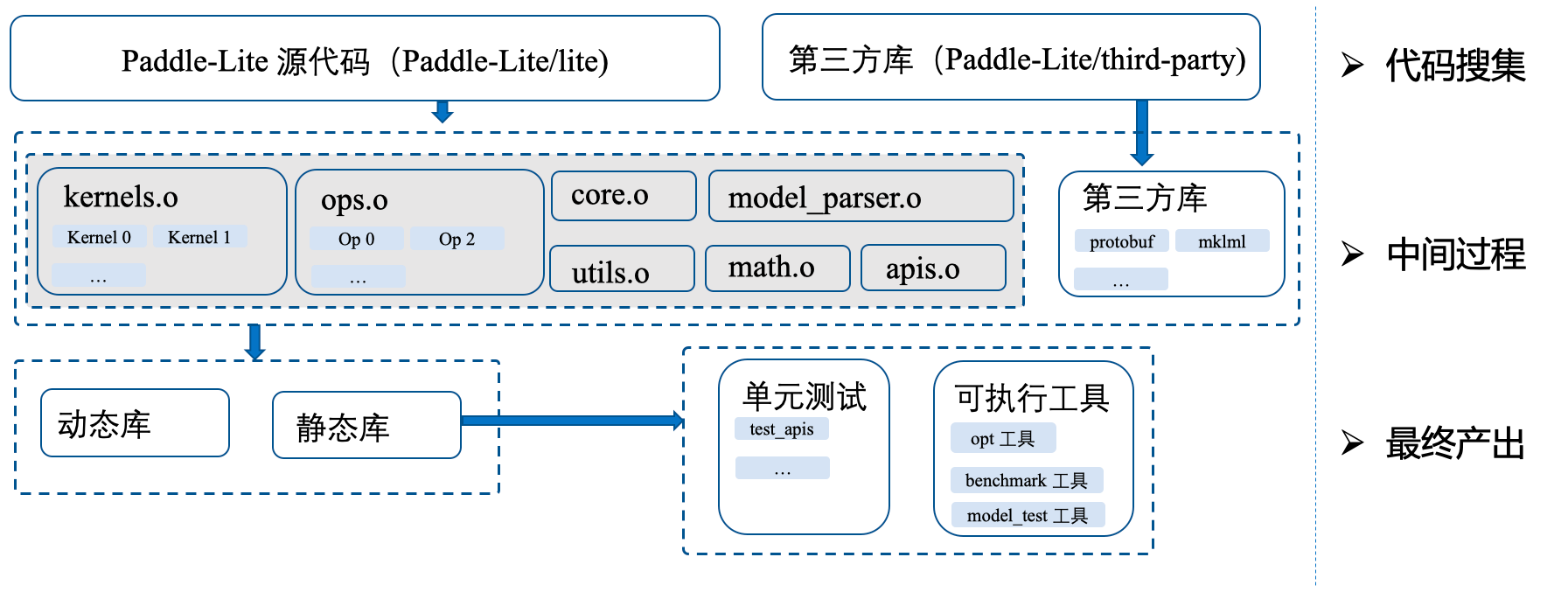
- 编译策略升级
- 精简代码结构:按功能代码整理、清理冗余代码
- 精简编译逻辑 :合并和复用部分编译逻辑,整体 cmake 代码量降低60%
- Benchmark 工具升级
- 多平台支持
- 支持 android 端 cpu、gpu 测速
- 支持 macOS 端 cpu、gpu 测速
- 支持 linux x86 端 cpu 测速
- 支持 linux arm 端 cpu、gpu 测速
- 支持 android 端 cpu、gpu 测速
- 多 backend 支持:已支持 cpu、gpu、各类 NPU
- 多平台支持
硬件&性能增强
ARM CPU
FP32 优化
- 新增 A53 v8 GEMM算子优化,kernel 性能有约 20%-40% 提升,详见 PR6521
- 新增 conv_3x3s2_direct C3 实现,kernel 性能有约 5%-10% 提升,详见PR6721
- 新增 A35 GEMV 算子优化实现,kernel性能有约 20%-40% 提升,详见PR6804
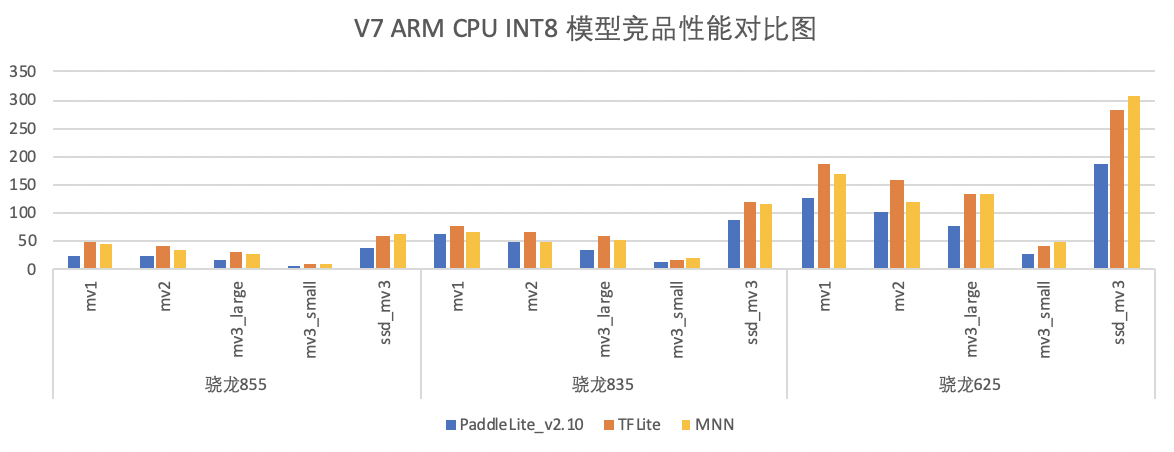
- 性能数据,以ARMv7 为例,以下为最新性能与竞品的对比:
-
FP32模型性能:低端机模型性能均优于竞品,高中端机模型性能部分优于竞品,部分差于竞品TFLite,在进一步优化中

-
INT8 模型性能:模型性能均优于竞品
-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large - ssd_mv3:
ssdlite_mobilenet_v3_large
- mv1:
-
竞品:
- PaddleLite分支:release/v2.10,7645e40(20211018)
- MNN分支:master,d21fd2a(20210904)
- TFLite分支:master,线上拉取最新(拉取日期:20210906),
- MD5 (
android_aarch64_benchmark_model) = 9851018013eb46ada7aedfad88f01da8 - MD5 (
android_arm_benchmark_model) = af6ca4bb724b9faa2370d307749f556a
- MD5 (
- TNN分支:master,40b88ce(20210903)
- MindsporeLite分支:master,155b2c0(20210830),
--cpuBindMode=1(大核)
-
FP16 优化
-
新增 V7 FP16 编译支持,要求 NDK 版本 21 及其以上
-
新增 V7 FP16 激活实现,如
relu、relu6、hard_swish等 -
新增 V7 FP16 Winograd 卷积、
calib、fill_bias_act等算子实现 -
新增
conv_3x3s2_directC3 实现,kernel 性能有5%-10% 提升,详见PR6726 -
新增 5+ V8 FP16 OP实现,如
box_clip、prior_box、hard_swish等实现 -
性能数据:
-
版本间性能对比:大部分模型有10%-30% 提升,详细性能数据请见下图

-
竞品性能对比:模型性能均优于竞品MNN 和 Mindspore-Lite,大部分模型性能与TNN 持平或稍差于,详细性能数据请见下图

-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large - ssd_mv3:
ssdlite_mobilenet_v3_large
- mv1:
-
竞品:
- PaddleLite分支:release/v2.10,7645e40(20211018)
- MNN分支:master,d21fd2a(20210904)
- TNN分支:master,40b88ce(20210903)
- MindsporeLite分支:master,155b2c0(20210830)
-
X86
-
新增10+ OP 算子支持,如
conv_transpoe、rnn、rduce_min、pow、mish等,跑通 Paddle 2.0 50+ 模型 -
新增 elementwise 的 broadcast 模式支持,详见PR6957
-
优化卷积中 bias + act 实现,卷积性能有1-2倍的提升,详见PR6704
-
优化3x3 depthwise卷积实现,对于MobilNetV1/V2性能提升约为20%,详见PR6745
-
-性能数据:
-
版本间性能对比:大部分模型性能有约20%-30% 提升,详细性能数据请见下图

-
测试机:Intel(R) Core(TM) i7-10700 CPU @ 2.90GHz
-
模型:
- mv1:
tf_mobilnetv1 - mv2:
tf_mobilnetv2 - mv3_small:
tf_mobilnetv3_small - mv3_large:
tf_mobilnetv3_large
- mv1:
-
-
新增 15个 OP,包括
anchor_generator,box_clip,conv2d_transpose,clip,generate_proposals / generate_proposals_v2,group_norm,nearest_interp_v2 / bilinear_interp_v2,mish,pow,rnn,roi_align,yolo_box,reduce_min,reverse,inverse.
OpenCL
-
GPU 基础能力提升
-
kernel 性能优化
- 优化 FC/Softmax:FC 可提速 1 ~ 3 倍,softmax可提速 44% ~ 302% #6560
-
Pass 相关
-
性能数据
- 与 release/v2.9.1 版本对比,多个模型在典型设备上有 ~5% 左右的性能提升;
- 与竞品对比,在大部分模型测试场景下,Paddle Lite 领先或持平与竞品,部分模型性能有待提高。
- 对应的各框架版本如下:
- Mindspore-Lite, master, ec2942a
- MNN, master, d21fd2a
- Paddle Lite, release/v2.10, 49f9e3f
- TFLite, 线上拉取 benchmark 工具(拉取日期:20210906)
- TNN, master, 40b88ce


Metal
- 新增 44 个 op&kernel , 详细列表请参考最新的 支持算子列表
- 支持 18 种 Paddle FP32 模型,已验证模型列表如下:

百度昆仑 xpu
- 编译优化
- 优化编译脚本,与 Paddle 统一 xpu_toolchain 依赖
- 编译脚本支持指定环境,编译时自动下载 xpu 依赖
- 支持 Windows + XPU 的预测库编译
- 模型支持能力
- 支持带控制流算子的模型
- 支持昆仑 xpu 内存和 L3 cache 复用策略,支持部分大内存模型,模型性能提升
- kernel 和 pass 支持
- 新增
__xpu_logit等 8 个 fuse pass - 新增
less_than,argmax等 65 个 kernel,详细列表请参考最新的 支持算子列表 - 3 个 kernel 新增支持 int8 精度计算
__xpu__conv2d__xpu__fc__xpu__multi_encoder
__xpu__embedding_with_eltwise_add支持 Mask 输入和 SeqLod、PadSeqLen 输出- 支持 calib 自动精度转换
- int64 --> int32
- int32 --> int64
- kernel cast 支持输入精度为 int32、int64
- kernel concat 支持输入包含维度为 0 的 tensor,支持输入精度为 int32、int64
- 新增
硬件支持
- 新增 NNAdapter:飞桨推理 AI 硬件统一适配框架,基于标准化的推理框架适配层 API 、硬件抽象层接口定义 和 模型、算子的中间表示 实现了推理框架与硬件适配完全解耦,可较为有效的降低硬件厂商接入门槛和开发成本,而更薄的硬件适配层 不仅能以较少的代码快速完成硬件适配,还可以提高代码的可维护性。目前已完成华为麒麟 NPU、瑞芯微 NPU、联发科 APU 和 颖脉 NNA 的迁移。

- 基于 NNAdapter 新增支持华为昇腾 NPU,完成 Intel x86 + Atlas 300I/C 3010、 昆鹏 920 + Atlas 300I/C 3000 的适配,支持 64 个算子和覆盖图像分类、目标检测、关键点检测、文本检测和识别、语义理解和生成网络共 32 个开源模型和 18 个业务模型。
- 基于 NNAdapter 新增支持晶晨NPU ,完成 Amlogic C308X (ARM Linux)、A311D(ARM Linux) 和 S905D3(Android)的适配,支持 MobileNetV1-int8-per_layer 开源模型和人体/手部关键点检测、人脸检测/识别/关键点检测等 11 个业务模型。
- 基于 NNAdapter + 瑞芯微 NPU 在 RK1808 EVB 上完成人体关键点检测业务模型的适配。
Bug fix
- 修复 conv opencl tune bug #6879 #6734
- 修复 conv_elementwise_tree_fuse_pass bug #6812
- 修复 host topk_v2 单测 bug #6629
- 修复 ssd_box_calc_offline pass 因 concat 的输入顺序的错误而导致的某些设备运行ssd类模型时随机挂问题 #6652
- 修复 Pad3dOpLite::InferShapeImpl() bug#6824
- 修复 tile op bug 和reduce_sum op bug #6487
- 修复 conv_transpose op 的计算分配空间不足问题,详见PR7287
- 修复 INT8 conv3x3s1_depthwise 计算错误,详见PR65667
- 修复 FP32 GEMM 算子read invalid 风险问题,详见PR7124
文档更新
- 更新了 Benchmark 工具使用说明和性能数据
- 新增 NNAdapter 文档