MADlib Benchmark Requirements
In order to well understand and be able to improve the performance of MADlib modules we need a proper benchmark framework. The purpose of this document is to lay out requirements for such a solution.
The main goals for MADlib benchmarks are:
-
Competitive comparison
Our initial comparison targets should be R and Mahout, as it should be easy to setup corresponding tests on the same HW configuration. Initial testing could be performed on a single host.
-
Regression tests and other purposes
We should keep a log book of current run-times and rerun the appropriate tests after any substantial modifications to existing modules. The summary of it should be available on the wiki.
-
Performance Improvements
The benchmark results should eventually be used to detect bottlenecks and to fix them.
In order to fulfill the above goals the MADlib benchmark tool should possess the following characteristics:
-
Portability
It must run on all OS and DB platforms supported by MADlib. Moreover, it needs to be possible to test other analytics utilities using the same command-line interface.
-
Scalability
It should be easy to scale the data size for a predefined test. This should apply to both tables dimensions as well as the run-time environment.
-
Reproducibility
It should be possible to rerun the performance test with identical starting conditions. This applies to both the data generation as well as the execution phase. All test parameters need to be recorded.
-
Modularity
It should be easy to add new performance tests for new or existing modules.
-
Automation
Execution of the benchmark (full or per module) should be easy to automate.
The initial comparison tests can be performed on a single machine using the following plan:
- HW/OS platform: 64 bit Red Hat Enterprise Linux Server 5.5 with 16 CPU cores, 64GB RAM.
-
Test environments:
- MADlib on Greenplum 4.1
- MADlib on PostgreSQL 9.0
- Alpine Miner on Greenplum 4.1
- R
- Hadoop/Mahout
-
Algorithms:
-
Naive-Bayes Classification: R, Mahout
Scaling factor: number of classes, attributes, rows.Training set size factors: nr of classes nr of attributes nr of rows Test 1: precompute class priors and feature probabilities, then score the data. Test 2: score the data w/o pre-computation of class priors and feature probabilities. -
Data set size factors: nr of independent variables nr of rows Test: run the linear regression function. -
Logistic Regression: R, Mahout
Data set size factors: nr of variables nr of rows Test: run the logistic regression function. -
Training set size factors: nr of clases nr of features nr of rows Test: run the decision tree training and score the new data. -
Support Vector Machines: R, Mahout
Training set size factors: nr of classes/labels nr of features/dimensions nr of rows/points Test: run the SVM training and data scoring for each of the following kernel functions: (1) regression, (2) classification, (3) novelty detection -
Data set size factors: nr of unique items nr of transactions max number of items per transaction Test: run the association rules function. -
Data set size factors: nr of points/rows nr of dimensions density/sparsity of data Test: run the k-means clustering function. -
SVD Matrix Factorisation: R, Mahout
Data set size factors: matrix dimensions (rows, columns) density/sparsity of data Test: run the matrix factorisation function. -
Latent Dirichlet Allocation: R, Mahout
Data set size factors: nr of documents nr of words per document size of the dictionary (nr of unique words) Test: run the LDA function.
-
- It should be possible to generate data in parallel. For instance, on a Greenplum system, the external-table loading should be supported.
- Whenever pseudo-random data is generated, the seed needs to be a parameter so that all tests are deterministic and reproducible.
- For optimal performance, it is desirable that data generators can be implementable easily in compiled languages like C or C++.
-
Usage of the performance benchmark tool should be similar to using madpack.
madtest <madtest options> -p <platform> <platform options> -b <benchmark> <benchmark options>For instance, for benchmarking linear regression on Greenplum, one would write
madtest -p greenplum -c localhost:5432/testdb -b LinearRegressionRandom --ivariables 10 --rows 20 --target_base_name bla -
Options should be modular. E.g., it should be possible to add options to a particular benchmark without haveing to make any modifications to madtest.
- Performance benchmark executions should be recorded for future reference, including as many parameters as possible that make each test reproducible.
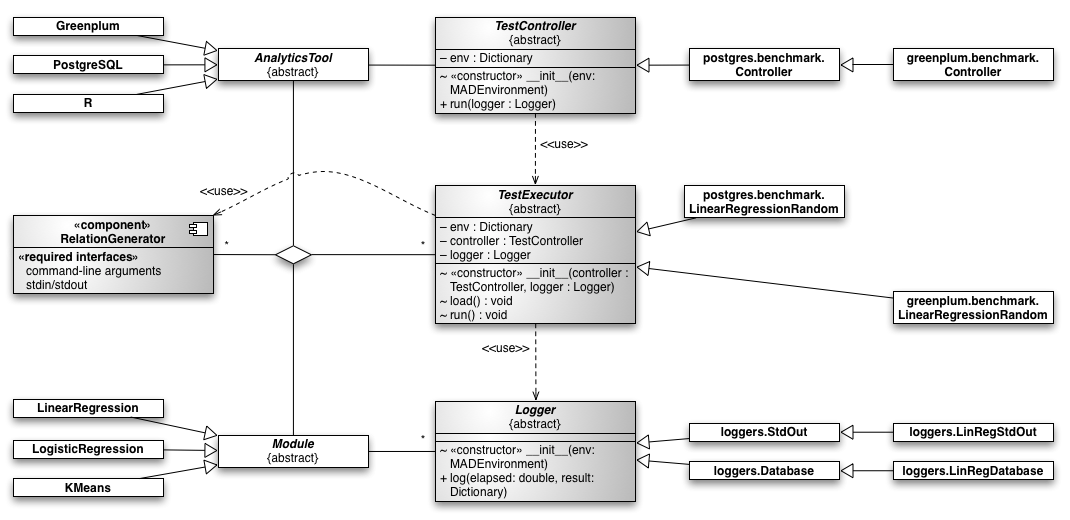
The following class diagram shows the high-level design. A shaded background indicates interfaces that need to be implemented for the various combinations of analytics tools and modules.
For each analytics tool:
- A test controller is implemented that drives data generation, data preprocessing/loading, and running the tests.
For each module:
- One or more loggers are implemented to process run-time statistics (usually, this means writing to persistant storage).
For each pair of analytics tool and module:
-
A relation generator is implemented that outputs the benchmark relations in a format usable by the respective analytics tool. The code for the data generation should not be analytics-tool specific, but instead be shared among all analaytics tools.
-
A test executor is implemented that feeds the output of the relation generator into the analytics tool. For instance, for Greenplum, this includes setting up external tables whose source is the stdout stream of the relation generator. Then normal table would be created with the same data, and further preparation steps would take place (like running
ANALYZEand flushing cashes). For other statistics software, the loading step is typically writing out the data in the appropriate input file format (which might be a binary format).After the loading, the benchmark test is executed, but calling the machine-learning algorithm with the newly-loaded data. The results and run-time statistics are then passed to the logger.